《OpenCV系列教程》
项目位置:OpenCV-Sample
代码位置:100-OCR.py
今天的博文我们将学习使用开源工具Tesseract+OpenCV,对图片上的文字进行识别。从图片提取文字的方法叫作“光学字符识别”(Optical Character Recognition )简称OCR,也可以简单的叫做文字识别。
Tesseract最初由惠普实验室开发,在2005年惠普与内华达拉斯维加斯大学进行合作的时候对其进行了开源。从2006年起,它被google和众多开源爱好者进行积极的开发和维护。
Tesseract在3.x版本的时候逐渐成熟,它支持多种图片格式并且大量的语言也被添加其中。但是Tesseract3.x是基于传统的计算机视觉算法的。过去的几年中,在众多的计算机视觉领域内,深度学习算法在精准程度上,明显优于传统的机器学习技术。手写识别就是一个很好的例证。因此Tesseract拥有一个基于深度学习的文字识别引擎只是一个时间的问题。
Tesseract在版本4的时候,就实现了一个基于Long Short Term Memory(LSTM网络)的识别引擎。LSTM是循环神经网络(Recurrent Neural Network)中的一种。
初学者需要主要:识别图片中的单个字符,我们通常使用卷积神经网络(Convolutional Neural Network)。但是对于任意长度的字符串呢?解决这个问题的方式使用Rnns和LSTM还是比较受欢迎的方式。这里能你更好的理解LSTM。
在Tesseract版本4中依旧留用了版本3中的OCR引擎,但LSTM变成了默认使用的识别引擎,在后面我们将使用后者进行识别。
Tesseract库附带了一个很方便的命令行工具叫做tesseract。我们可以通过这个工具进行OCR文字识别,并且输出存在在一个txt文件中。如果你想在代码中使用Tesseract你就需要调用他的API。在使用之前我们需要先安装上它。
如何在Ubuntu和macOS上安装Tesseract
安装如下:
- Tesseract library (libtesseract)
- Tesseract命令行工具 (tesseract-ocr)
- 被Python包装的tesseract (pytesseract)
在教程的后面,我们还会讨论如何安装英语之外的语言脚步文件。
1.1 在Ubuntu18.04上安装Tesseract 4.0
Tesseract已经被Ubuntu18.04内置,所有我们可以直接安装。
sudo apt install tesseract-ocr
sudo apt install libtesseract-dev
sudo apt install tesseract-ocr-chi-sim #对中文的支持
sudo apt install tesseract-ocr-eng #英文的支持
sudo pip install pytesseract
1.2在Ubuntu 17.04、 17.10、 16.04、 14.04上安装Tesseract 4.0
因为依赖关系,比18.04老的版本中,仅仅Tesseract3是有效的。
幸运的是Ubuntu PPA – alex-p/tesseract-ocr 支持了Ubuntu versions 14.04, 16.04, 17.04, 17.10。我们可以添加PPA到我们的系统中,然后进行安装。如果你的ubuntu版本不是上面所述中的任一个,你则需要通过源码编译。
sudo add-apt-repository ppa:alex-p/tesseract-ocr
sudo apt-get update
sudo apt install tesseract-ocr
sudo apt install libtesseract-dev
sudo pip install pytesseract
1.3 在MacOS上安装Tensseract4.0
我们将使用Homebrew来安装Tesseract。默认Homebrew安装的是Tesseract 3,但我们可以让他安装最新版本。使用如下命令:
# If you have tesseract 3 installed, unlink first by uncommenting the line below
# brew unlink tesseract
brew install tesseract --HEAD
pip install pytesseract
1.4 查看Tesseract版本信息
上述的步骤如果我们都做对了,就可以运行下面的命令了
tesseract --version
你会看到类似的输出:
tesseract 4.0.0-115-ge3a3
leptonica-1.76.0
libgif 5.1.4 : libjpeg 8d (libjpeg-turbo 1.4.2) : libpng 1.2.54 : libtiff 4.0.6 : zlib 1.2.8 : libwebp 0.4.4 : libopenjp2 2.3.0
Found AVX2
Found AVX
Found SSE
2. Tesseract的基本使用
正如先前提到的,我们使用命令行工具或者在我们的C++、Python中调用API接口。非常基础的使用,我们指定如下内容:
- Input filename:我们使用带有文字的图片作为输入。
- OCR language:语言在我们的小例子中需要设置语言,这个例子设置成英文。通过命令行“tesseract –list-langs”可以进行查看。
- OCR Engine Mode (oem):Tesseract 4 有两个OCR引擎。一个是Tesseract遗留下来的引擎,另个是比较先进的LSTM引擎。这里有四个操作模式通过–oem进行选择。
0 Legacy engine only.
1 Neural nets LSTM engine only.
2 Legacy + LSTM engines.
3 Default, based on what is available.
- Page Segmentation Mode (psm):当你给文本结构添加附加信息的时候,PSM会边的非常有用。我们将在后续教程中讨论其中的一些模式。在这个教程中我们将其设置为psm=3
提示:当PSM没有不指定的时候,它的默认值是3.
2.1 在命令行中使用
下面的例子展示了tesseract命令行工具,如何执行OCR操作。 语言选择为英语,OCR引擎设置为1(LSTM)
# Output to terminal
tesseract image.jpg stdout -l eng --oem 1 --psm 3
# Output to output.txt
tesseract image.jpg output -l eng --oem 1 --psm 3
2.2 使用 pytesseract
使用Python编程的时候我们使用pytesseract模块。他是命令行工具的简易包装器,通过config这个参数来指定命令行选项。基本操作是我们使用OpenCV提取图像,并将图像转给 pytesseract类中的,image_to_string方法。
import cv2
import sys
import pytesseract
if __name__ == '__main__':
if len(sys.argv) < 2:
print('Usage: python ocr_simple.py image.jpg')
sys.exit(1)
# Read image path from command line
imPath = sys.argv[1]
# Uncomment the line below to provide path to tesseract manually
# pytesseract.pytesseract.tesseract_cmd = '/usr/bin/tesseract'
# Define config parameters.
# '-l eng' for using the English language
# '--oem 1' for using LSTM OCR Engine
config = ('-l eng --oem 1 --psm 3')
# Read image from disk
im = cv2.imread(imPath, cv2.IMREAD_COLOR)
# Run tesseract OCR on image
text = pytesseract.image_to_string(im, config=config)
# Print recognized text
print(text)
2.3 通过C++调用API
在C++版本中,我们首先需要include tesseract/baseapi.h和leptonica/allheaders.h。我们创建了一个指向TessBaseAPI的实例。我们初始化英文(eng)并且选择tesseract::OEM_LSTM_ONLY(命令行操作对应的是 –oem 1)。最后我们使用OpenCV读取图片,对这个图片使用引擎的SetImage方法。输出的字符串使用GetUTFText()函数。
#include <string>
#include <tesseract/baseapi.h>
#include <leptonica/allheaders.h>
#include <opencv2/opencv.hpp>
using namespace std;
using namespace cv;
int main(int argc, char* argv[])
{
string outText;
string imPath = argv[1];
// Create Tesseract object
tesseract::TessBaseAPI *ocr = new tesseract::TessBaseAPI();
// Initialize tesseract to use English (eng) and the LSTM OCR engine.
ocr->Init(NULL, "eng", tesseract::OEM_LSTM_ONLY);
// Set Page segmentation mode to PSM_AUTO (3)
ocr->SetPageSegMode(tesseract::PSM_AUTO);
// Open input image using OpenCV
Mat im = cv::imread(imPath, IMREAD_COLOR);
// Set image data
ocr->SetImage(im.data, im.cols, im.rows, 3, im.step);
// Run Tesseract OCR on image
outText = string(ocr->GetUTF8Text());
// print recognized text
cout << outText << endl; // Destroy used object and release memory ocr->End();
return EXIT_SUCCESS;
}
你可以通过下面的命令行编译代码:
g++ -O3 -std=c++11 ocr_simple.cpp `pkg-config --cflags --libs tesseract opencv`-o ocr_simple
展示效果:

打印输出:
1
章程序员书库 es
IT后王汪局 扩玫1
管区册让全这
Learning OpenCV 3 Compnuter Vision with Python
ut
[爱尔兰] 乔. 米尼奇诺 ( Joe Minichino ) 3
了
刘波 苗贝贝 史斌 译
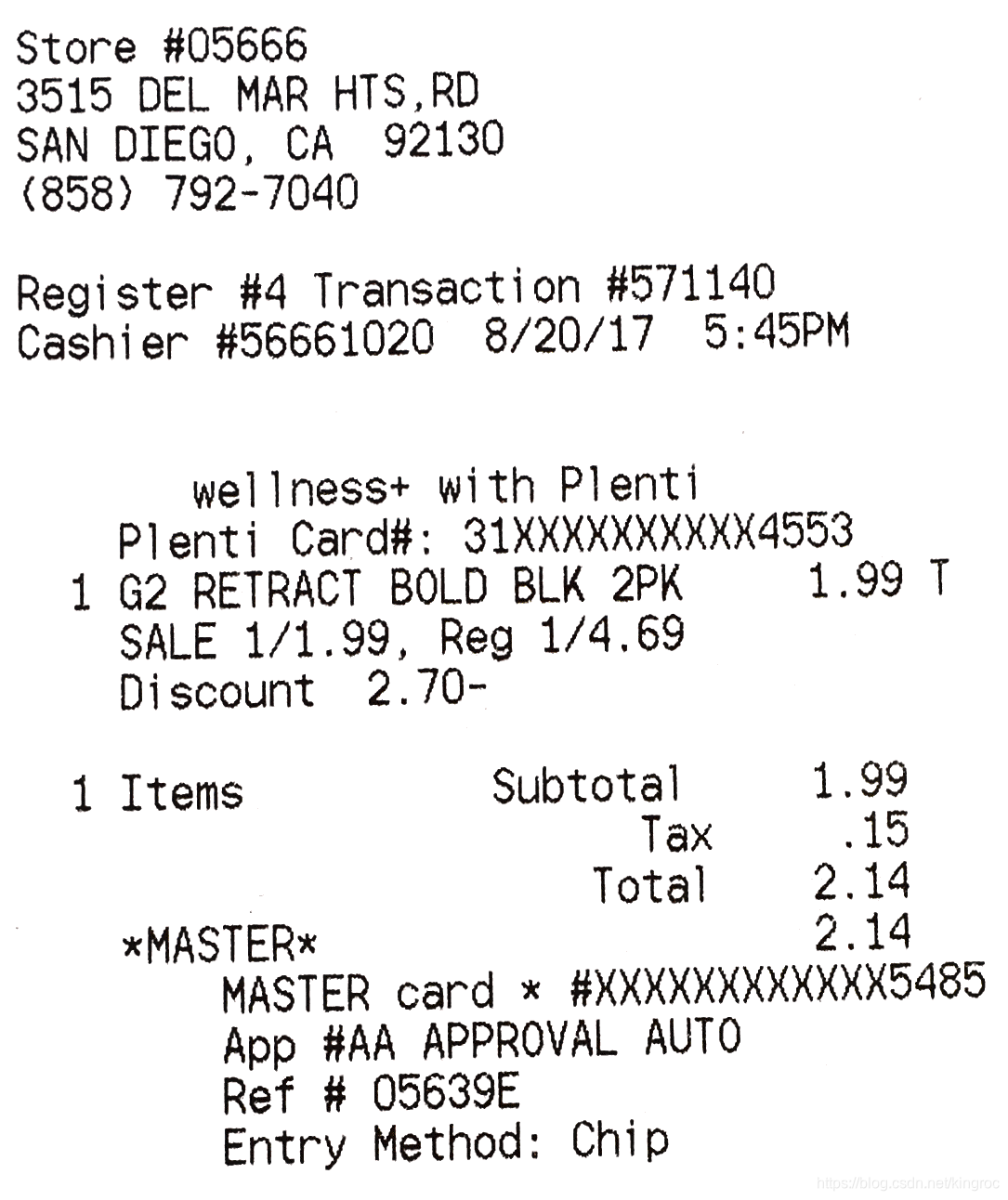
输出:
Output
Store #056663515
DEL MAR HTS,RD
SAN DIEGO, CA 92130
(858) 792-7040Register #4 Transaction #571140
Cashier #56661020 8/20/17 5:45PMwellnesst+ with Plenti
Plenti Card#: 31XXXXXXXXXX4553
1 G2 RETRACT BOLD BLK 2PK 1.99 T
SALE 1/1.99, Reg 1/4.69
Discount 2.70-
1 Items Subtotal 1.99
Tax .15
Total 2.14
*xMASTER* 2.14
MASTER card * #XXXXXXXXXXXX548S
Apo #AA APPROVAL AUTO
Ref # 05639E
Entry Method: Chip

输出:
Output
SKATEBOARDING
BICYCLE RIDING
ROLLER BLADING
SCOOTER RIDING
®
原文地址:https://www.learnopencv.com/deep-learning-based-text-recognition-ocr-using-tesseract-and-opencv/
作者:王小鹏鹏
原文链接:https://blog.csdn.net/kingroc/article/details/85230233
转载请注明:www.ainoob.cn » [译]基于深度学习的文字识别(OCR)通过Tesseract+OpenCV实现




