我在第一版的《零基础学python》中,这个标题前面加了“坑爹”两个字。在后来的实践中,很多朋友都在网上问我关于编码的事情。说明这的确是一个“坑”。
首先说明,在python2中,编码问题的确有点麻烦。但是,python3就不用纠结于此了。但是,正如前面所说的原因,至少本教程还是用python2,所以,必须要搞清楚编码。当然了,搞清楚,也不是坏事。
字符编码,在编程中,是一个让学习者比较郁闷的东西,比如一个str,如果都是英文,好说多了。但恰恰不是如此,中文是我们不得不用的。所以,哪怕是初学者,都要了解并能够解决字符编码问题。
>>> name = '老齐'
>>> name
'\xe8\x80\x81\xe9\xbd\x90'
在你的编程中,你遇到过上面的情形吗?认识最下面一行打印出来的东西吗?看人家英文,就好多了
>>> name = "qiwsir"
>>> name
'qiwsir'
难道这是中文的错吗?看来投胎真的是一个技术活。是的,投胎是技术活,但上面的问题不是中文的错。
编码
什么是编码?这是一个比较玄乎的问题。也不好下一个普通定义。我看到有的教材中有定义,不敢说他的定义不对,至少可以说不容易理解。
古代打仗,击鼓进攻、鸣金收兵,这就是编码。把要传达给士兵的命令对应为一定的其它形式,比如命令“进攻”,经过如此的信息传递:
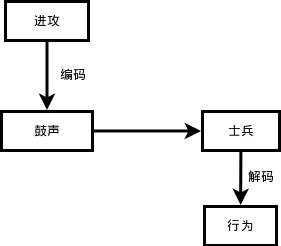
- 长官下达进攻命令,传令员将这个命令编码为鼓声(如果复杂点,是不是有几声鼓响,如何进攻呢?)。
- 鼓声在空气中传播,比传令员的嗓子吼出来的声音传播的更远,士兵听到后也不会引起歧义,一般不会有士兵把鼓声当做打呼噜的声音。这就是“进攻”命令被编码成鼓声之后的优势所在。
- 士兵听到鼓声,就是接收到信息之后,如果接受过训练或者有人告诉过他们,他们就知道这是让我进攻。这个过程就是解码。所以,编码方案要有两套。一套在信息发出者那里,另外一套在信息接受者这里。经过解码之后,士兵明白了,才行动。
以上过程比较简单。其实,真实的编码和解码过程,要复杂了。不过,原理都差不多的。
举一个似乎遥远,其实不久前人们都在使用的东西做例子:电报
列位看官注意了,这里出现了电报中用的“中文电码”,这就是一种编码,将汉字对应成阿拉伯数字,从而能够用电报发送汉字。
电报中的编码被称为摩尔斯电码,英文是Morse Code
看来电报员是一个技术活,不同长短的停顿都代表了不同意思。哦,对了,有一个老片子《永不消逝的电波》,看完之后保证你才知道,里面根本就没有讲电报是怎么编码的。

我瞪着眼看了老长时间,这两行不是一样的吗?
不管这个了,总之,这就是编码。
计算机中的字符编码
先抄一段维基百科对字符编码的解释:
在这个世界上,有好多不同的字符编码。但是,它们不是自己随便搞搞的。而是要有一定的基础,往往是以名叫ASCII的编码为基础,这里边也应该包括北朝鲜吧(不知道他们用什么字符编码,瞎想的,别当真,不代表本教材立场,只代表瞎想)。
上面的引文中已经说了,现在我们用的编码标准已经变成Unicode了,那么什么是Unicode呢?还是抄一段来自维基百科的说明
听这名字:万国码,那就一定包含了中文喽。的确是。但是,光有一个Unicode还不行,因为….(此处省略若干字,看官可以到上面给出的维基百科链接中看),还要有其它的一些编码实现方式,Unicode的实现方式称为Unicode转换格式(Unicode Transformation Format,简称为UTF),于是乎有了一个我们在很多时候都会看到的utf-8。
什么是utf-8,还是看维基百科上怎么说的吧
不再多引用了,如果要看更多,请到原文。
看官现在是不是就理解了,前面写程序的时候,曾经出现过:coding:utf-8的字样。就是在告诉python我们要用什么字符编码呢。
encode和decode
历史部分说完了,接下怎么讲?比较麻烦了。因为不管怎么讲,都不是三言两语说清楚的。姑且从encode()和decode()两个内置函数起吧。
python2默认的编码是ascii,通过encode可以将对象的编码转换为指定编码格式(称作“编码”),而decode是这个过程的逆过程(称作“解码”)。
做一个实验,才能理解:
>>> a = "中"
>>> type(a)
<type 'str'>
>>> a
'\xe4\xb8\xad'
>>> len(a)
3
>>> b = a.decode()
>>> b
u'\u4e2d'
>>> type(b)
<type 'unicode'>
>>> len(b)
1
这个实验不做之前,或许看官还不是很迷茫(因为不知道,知道的越多越迷茫),实验做完了,自己也迷茫了。别急躁,对编码问题的理解,要慢慢来,如果一时理解不了,也肯定理解不了,就先注意按照要求做,做着做着就豁然开朗了。
上面试验中,变量a引用了一个字符串,所谓字符串(str),严格地将是字节串,它是经过编码后的字节组成的序列。也就是你在上面的实验中,看到的是“中”这个字在计算机中编码之后的字节表示。(关于字节,看官可以google一下)。用len(a)来度量它的长度,它是由三个字节组成的。
然后通过decode函数,将字节串转变为字符串,并且这个字符串是按照unicode编码的。在unicode编码中,一个汉字对应一个字符,这时候度量它的长度就是1.
反过来,一个unicode编码的字符串,也可以转换为字节串。
>>> c = b.encode('utf-8')
>>> c
'\xe4\xb8\xad'
>>> type(c)
<type 'str'>
>>> c == a
True
关于编码问题,先到这里,点到为止吧。因为再扯,还会扯出问题来。看官肯定感到不满意,因为还没有知其所以然。没关系,请尽情google,即可解决。
python中如何避免中文是乱码
这个问题是一个具有很强操作性的问题。我这里有一个经验总结,分享一下,供参考:
首先,提倡使用utf-8编码方案,因为它跨平台不错。
经验一:在开头声明:
# -*- coding: utf-8 -*-
有朋友问我-*-有什么作用,那个就是为了好看,爱美之心人皆有,更何况程序员?当然,也可以写成:
# coding:utf-8
经验二:遇到字符(节)串,立刻转化为unicode,不要用str(),直接使用unicode()
unicode_str = unicode('中文', encoding='utf-8')
print unicode_str.encode('utf-8')
经验三:如果对文件操作,打开文件的时候,最好用codecs.open,替代open(这个后面会讲到,先放在这里)
import codecs
codecs.open('filename', encoding='utf8')
经验四:声明字符串直接加u,声明的字符串就是unicode编码的字符串
a = u"中"
我还收集了网上的一片文章,也挺好的,推荐给看官:Python2.x的中文显示方法
最后告诉给我,如果用python3,坑爹的编码问题就不烦恼了。
转载请注明:www.ainoob.cn » 零基础学Python:字符编码




