还记得在《迭代》中提到的那几个说出来就让人感觉牛X的名词吗?前面已经学习过“循环”、“遍历”和“迭代”了。现在来看“递归”。
递归
什么是递归?
这是对“递归”最精简的定义。还有故事类型的定义.
如果用上面的做递归的定义,总感觉有点调侃,来个严肃的(选自维基百科):
最典型的递归例子之一是斐波那契数列,虽然前面用迭代的方式实现了它,但是那种方法在理解上不很直接。如果忘记了这个数列的定义,可以回到《练习》中查看。
根据斐波那契数列的定义,可以直接写成这样的斐波那契数列递归函数。
#!/usr/bin/env python
# coding=utf-8
def fib(n):
"""
This is Fibonacci by Recursion.
"""
if n==0:
return 0
elif n==1:
return 1
else:
return fib(n-1) + fib(n-2)
if __name__ == "__main__":
f = fib(10)
print f
把上述代码保存。这个代码的意图是要得到n=10的值。运行之:
$ python 20401.py
55
fib(n-1) + fib(n-2)就是又调用了这个函数自己,实现递归。为了明确递归的过程,下面走一个计算过程(考虑到次数不能太多,就让n=3)
- n=3,fib(3),自然要走
return fib(3-1) + fib(3-2)分支 - 先看fib(3-1),即fib(2),也要走else分支,于是计算
fib(2-1) + fib(2-2) - fib(2-1)即fib(1),在函数中就要走elif分支,返回1,即fib(2-1)=1。同理,容易得到fib(2-2)=0。将这两个值返回到上面一步。得到
fib(3-1)=1+0=1 - 再计算fib(3-2),就简单了一些,返回的值是1,即fib(3-2)=1
- 最后计算第一步中的结果:
fib(3-1) + fib(3-2) = 1 + 1 = 2,将计算结果2作为返回值
从而得到fib(3)的结果是2。
从上面的过程中可以看出,每个递归的过程,都是向着最初的已知条件a0=0,a1=1方向挺近一步,直到通过这个最底层的条件得到结果,然后再一层一层向上回馈计算机结果。
其实,上面的代码有一个问题。因为a0=0,a1=1是已知的了,不需要每次都判断一边。所以,还可以优化一下。优化的基本方案就是初始化最初的两个值。
#!/usr/bin/env python
# coding=utf-8
"""
the better Fibonacci
"""
meno = {0:0, 1:1} #初始化
def fib(n):
if not n in meno: #如果不在初始化范围内
meno[n] = fib(n-1) + fib(n-2)
return meno[n]
if __name__ == "__main__":
f = fib(10)
print f
#运行结果
$ python 20402.py
55
以上实现了递归,但是,至少在python中,递归要慎重使用。在一般情况下,递归是能够被迭代或者循环替代的,而且后者的效率常常比递归要高。所以,我个人的建议是,对使用递归要考虑的周密一下,不小心就永远运行下去了。
几个特殊函数
前面已经知道了如何编写、调用函数。此外,在python中,有几个特别的函数,很有意思,它们常常被看做是python能够进行所谓“函数式编程”的见证。
不管读者是初学还是老油条,都建议将上面这段话认真读完,不管理解还是不理解,总能有点感觉的。
正如前面引文中所说的,python是支持多种范型的语言,可以进行所谓函数式编程,其突出体现在有这么几个函数:
filter、map、reduce、lambda、yield
有了它们,最大的好处是程序更简洁;没有它们,程序也可以用别的方式实现,只不过麻烦一些罢了。所以,还是能用则用之吧。更何况,恰当地使用这几个函数,能让别人感觉你更牛X。
(注:本节不对yield进行介绍,请阅读《生成器》)
lambda
lambda函数,是一个只用一行就能解决问题的函数,听着是多么诱人呀。看下面的例子:
>>> def add(x): #定义一个函数,将输入的变量增加3,然后返回增加之后的值
... x += 3
... return x
...
>>> numbers = range(10)
>>> numbers
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9] #有这样一个list,想让每个数字增加3,然后输出到一个新的list中
>>> new_numbers = []
>>> for i in numbers:
... new_numbers.append(add(i)) #调用add()函数,并append到list中
...
>>> new_numbers
[3, 4, 5, 6, 7, 8, 9, 10, 11, 12]
在这个例子中,add()只是一个中间操作。当然,上面的例子完全可以用别的方式实现。比如:
>>> new_numbers = [ i+3 for i in numbers ]
>>> new_numbers
[3, 4, 5, 6, 7, 8, 9, 10, 11, 12]
首先说明,这种列表解析的方式是非常非常好的。
但是,我们偏偏要用lambda这个函数替代add(x),如果看官和我一样这么偏执,就可以:
>>> lam = lambda x:x+3
>>> n2 = []
>>> for i in numbers:
... n2.append(lam(i))
...
>>> n2
[3, 4, 5, 6, 7, 8, 9, 10, 11, 12]
这里的lam就相当于add(x),请看官对应一下,这一行lambda x:x+3就完成add(x)的三行(还是两行?),特别是最后返回值。还可以写这样的例子:
>>> g = lambda x,y:x+y #x+y,并返回结果
>>> g(3,4)
7
>>> (lambda x:x**2)(4) #返回4的平方
16
通过上面例子,总结一下lambda函数的使用方法:
- 在lambda后面直接跟变量
- 变量后面是冒号
- 冒号后面是表达式,表达式计算结果就是本函数的返回值
为了简明扼要,用一个式子表示是必要的:
lambda arg1, arg2, ...argN : expression using arguments
要特别提醒看官:虽然lambda 函数可以接收任意多个参数 (包括可选参数) 并且返回单个表达式的值,但是lambda 函数不能包含命令,包含的表达式不能超过一个。不要试图向 lambda 函数中塞入太多的东西;如果你需要更复杂的东西,应该定义一个普通函数,然后想让它多长就多长。
就lambda而言,它并没有给程序带来性能上的提升,它带来的是代码的简洁。比如,要打印一个list,里面依次是某个数字的1次方,二次方,三次方,四次方。用lambda可以这样做:
>>> lamb = [ lambda x:x,lambda x:x**2,lambda x:x**3,lambda x:x**4 ]
>>> for i in lamb:
... print i(3),
...
3 9 27 81
lambda做为一个单行的函数,在编程实践中,可以选择使用。
map
先看一个例子,还是上面讲述lambda的时候第一个例子,用map也能够实现:
>>> numbers
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9] #把列表中每一项都加3
>>> map(add,numbers) #add(x)是上面讲述的那个函数,但是这里只引用函数名称即可
[3, 4, 5, 6, 7, 8, 9, 10, 11, 12]
>>> map(lambda x: x+3,numbers) #用lambda当然可以啦
[3, 4, 5, 6, 7, 8, 9, 10, 11, 12]
map()是python的一个内置函数,它的基本样式是:
map(func,seq)
func是一个函数,seq是一个序列对象。在执行的时候,序列对象中的每个元素,按照从左到右的顺序,依次被取出来,并塞入到func那个函数里面,并将func的返回值依次存到一个list中。
在应用中,map的所能实现的,也可以用别的方式实现。比如:
>>> items = [1,2,3,4,5]
>>> squared = []
>>> for i in items:
... squared.append(i**2)
...
>>> squared
[1, 4, 9, 16, 25]
>>> def sqr(x): return x**2
...
>>> map(sqr,items)
[1, 4, 9, 16, 25]
>>> map(lambda x: x**2, items)
[1, 4, 9, 16, 25]
>>> [ x**2 for x in items ] #这个我最喜欢了,一般情况下速度足够快,而且可读性强
[1, 4, 9, 16, 25]
条条大路通罗马,以上方法,在编程中,自己根据需要来选用啦。
在以上感性认识的基础上,在来浏览有关map()的官方说明,能够更明白一些。
理解要点:
- 对iterable中的每个元素,依次应用function的方法(函数)(这本质上就是一个for循环)。
- 将所有结果返回一个list。
- 如果参数很多,则对那些参数并行执行function。
例如:
>>> lst1 = [1,2,3,4,5]
>>> lst2 = [6,7,8,9,0]
>>> map(lambda x,y: x+y, lst1,lst2) #将两个列表中的对应项加起来,并返回一个结果列表
[7, 9, 11, 13, 5]
请看官注意了,上面这个例子如果用for循环来写,还不是很难,如果扩展一下,下面的例子用for来改写,就要小心了:
>>> lst1 = [1,2,3,4,5]
>>> lst2 = [6,7,8,9,0]
>>> lst3 = [7,8,9,2,1]
>>> map(lambda x,y,z: x+y+z, lst1,lst2,lst3)
[14, 17, 20, 15, 6]
这才显示出map的简洁优雅。
reduce
直接看这个:
>>> reduce(lambda x,y: x+y,[1,2,3,4,5])
15
请看官仔细观察,是否能够看出是如何运算的呢?画一个图:
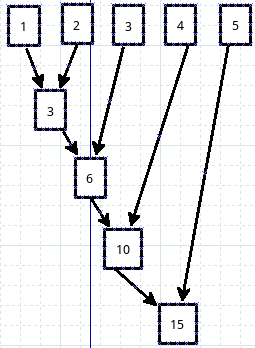
还记得map是怎么运算的吗?忘了?看代码:
>>> list1 = [1,2,3,4,5,6,7,8,9]
>>> list2 = [9,8,7,6,5,4,3,2,1]
>>> map(lambda x,y: x+y, list1,list2)
[10, 10, 10, 10, 10, 10, 10, 10, 10]
看官对比一下,就知道两个的区别了。原来map是上下运算,reduce是横着逐个元素进行运算。
权威的解释来自官网:
def reduce(function, iterable, initializer=None):
it = iter(iterable)
if initializer is None:
try:
initializer = next(it)
except StopIteration:
raise TypeError('reduce() of empty sequence with no initial value')
accum_value = initializer
for x in it:
accum_value = function(accum_value, x)
return accum_value
如果用我们熟悉的for循环来做上面reduce的事情,可以这样来做:
>>> lst = range(1,6)
>>> lst
[1, 2, 3, 4, 5]
>>> r = 0
>>> for i in range(len(lst)):
... r += lst[i]
...
>>> r
15
for普世的,reduce是简洁的。
为了锻炼思维,看这么一个问题,有两个list,a = [3,9,8,5,2],b=[1,4,9,2,6],计算:a[0]b[0]+a[1]b[1]+…的结果。
>>> a
[3, 9, 8, 5, 2]
>>> b
[1, 4, 9, 2, 6]
>>> zip(a,b) #复习一下zip,下面的方法中要用到
[(3, 1), (9, 4), (8, 9), (5, 2), (2, 6)]
>>> sum(x*y for x,y in zip(a,b)) #解析后直接求和
133
>>> new_list = [x*y for x,y in zip(a,b)] #可以看做是上面方法的分布实施
>>> #这样解析也可以:new_tuple = (x*y for x,y in zip(a,b))
>>> new_list
[3, 36, 72, 10, 12]
>>> sum(new_list) #或者:sum(new_tuple)
133
>>> reduce(lambda sum,(x,y): sum+x*y,zip(a,b),0) #这个方法是在耍酷呢吗?
133
>>> from operator import add,mul #耍酷的方法也不止一个
>>> reduce(add,map(mul,a,b))
133
>>> reduce(lambda x,y: x+y, map(lambda x,y: x*y, a,b)) #map,reduce,lambda都齐全了,更酷吗?
133
最后,要特别提醒:如果读者使用的是python3,跟上面有点不一样,因为在python3中,reduce()已经从全局命名空间中移除,放到了functools模块中,如果要是用,需要用from functools import reduce引入之。
filter
filter的中文含义是“过滤器”,在python中,它就是起到了过滤器的作用。首先看官方说明:
这次真的不翻译了(好像以往也没有怎么翻译呀),而且也不解释要点了。请列位务必自己阅读上面的文字,并且理解其含义。英语,无论怎么强调都是不过分的,哪怕是做乞丐,说两句英语,没准还可以讨到英镑美元呢。
通过下面代码体会:
>>> numbers = range(-5,5)
>>> numbers
[-5, -4, -3, -2, -1, 0, 1, 2, 3, 4]
>>> filter(lambda x: x>0, numbers)
[1, 2, 3, 4]
>>> [x for x in numbers if x>0] #与上面那句等效
[1, 2, 3, 4]
>>> filter(lambda c: c!='i', 'qiwsir') #能不能对应上面文档说明那句话呢?
'qwsr' #“If iterable is a string or a tuple, the result also has that type;”
至此,介绍了几个函数,这些函数在对程序的性能提高上,并没有显著或者稳定预期,但是,在代码的简洁上,是有目共睹的。有时候是可以用来秀一秀,彰显python的优雅和自己耍酷。如何用、怎么用,看你自己的喜好了。
转载请注明:www.ainoob.cn » 零基础学Python:函数(4)




