一、scrapy xpath 属性提取
这里先给大家列出xpath的选择器类型,如下表:XPath 使用路径表达式在 XML 文档中选取节点。节点是通过沿着路径或者 step 来选取的。 下面列出了最有用的路径表达式:

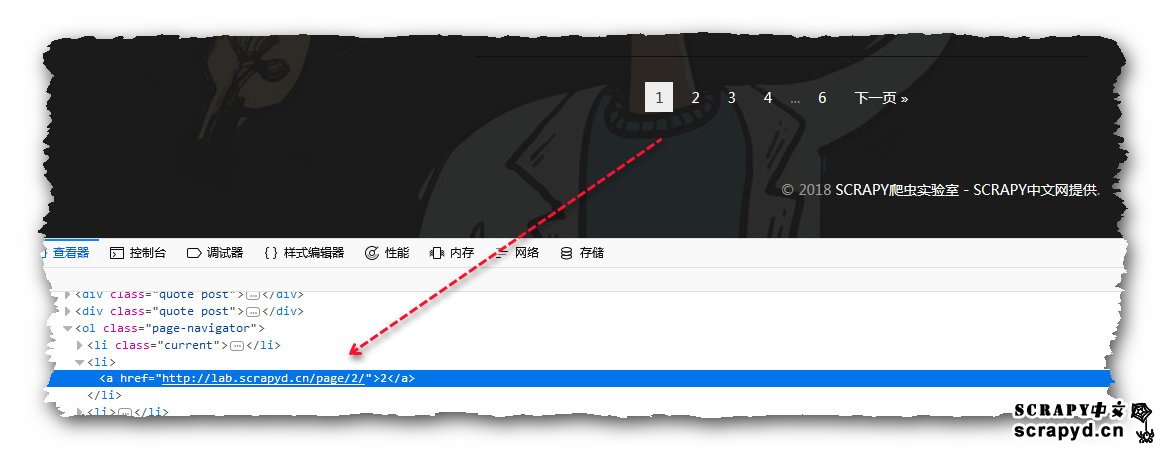
上面神马意思或许你还不清楚,没关系,1+1为神马等于2我们也无法证明,会用即可;可以看到上面选取属性用的是:@符号,那我们还是来试试提取最常见的属性:href、src,首先我们试着来提取href,还是用:http://lab.scrapy.cn开刀,就提取首页分页的href,如下图:
调试的话我们还是在命令行使用下面命令:
scrapy shell lab.scrapyd.cn
这样的话就能成功打开lab.scrapyd.cn这个页面,那我们要如何使用xpath表达式呢?用到了这么一个函数:response.xpath(“表达式”),提取属性的话既然使用:@,那我们要提取href就是:@href,试一下:
In [1]: response.xpath("@href")
Out[1]: []
可以看到神马都木有,why?因为我们木有限定从哪里提取,一般我们都需要加个://,再来试试
In [2]: response.xpath("//@href")
Out[2]:
[<Selector xpath='//@href' data='//cdnjscn.b0.upaiyun.com/libs/normalize/'>,
<Selector xpath='//@href' data='http://lab.scrapyd.cn/usr/themes/default'>,
……
<Selector xpath='//@href' data='http://lab.scrapyd.cn/tag/%E7%8E%8B%E5%B'>,
<Selector xpath='//@href' data='http://lab.scrapyd.cn/tag/%E6%99%BA%E6%8'>,
<Selector xpath='//@href' data='http://lab.scrapyd.cn/tag/%E6%B3%B0%E6%8'>,
……
<Selector xpath='//@href' data='http://lab.scrapyd.cn/tag/%E8%AF%8D/'>,
<Selector xpath='//@href' data='http://lab.scrapyd.cn'>,
<Selector xpath='//@href' data='http://bbs.scrapyd.cn'>,
<Selector xpath='//@href' data='http://www.scrapyd.cn'>,
<Selector xpath='//@href' data='http://lab.scrapyd.cn/'>]
可以看到已经提取到了,只是这是这个页面所有的href,并非是我们想要的,那和css选择一样我们需要加以限制,如何限制呢?我们可以看到分页href是在一个<ol></ol>标签里面,那我们就可以这样来写:
In [9]: response.xpath("//ol//@href")
Out[9]:
[<Selector xpath='//ol//@href' data='http://lab.scrapyd.cn/page/1/'>,
<Selector xpath='//ol//@href' data='http://lab.scrapyd.cn/page/2/'>,
<Selector xpath='//ol//@href' data='http://lab.scrapyd.cn/page/3/'>,
<Selector xpath='//ol//@href' data='http://lab.scrapyd.cn/page/4/'>,
<Selector xpath='//ol//@href' data='http://lab.scrapyd.cn/page/6/'>,
<Selector xpath='//ol//@href' data='http://lab.scrapyd.cn/page/2/'>]
“//ol//@href”,这个表达式表示:ol标签下所有的href属性值,可以看到我们这里限定了html的<ol>标签,这里的话页面只有一个<ol>,不会出错,如果页面中有多个<ol>,那就不一定能得到我们想要的结果,那如何是好?这里我们还能限定我们的属性,使用的是:标签[@属性名=’属性值’]; 例如,我们分页标签:
<ol class="page-navigator"> …… </ol>
里面有个:class=“page-navigator”,那我们就可以这样限制://ol[@class=”page-navigator”]//@href 好了,这样的话就能让<ol>尽量缩小范围,我们再来试试这个代码效果:
In [10]: response.xpath("//ol[@class='page-navigator']//@href")
Out[10]:
[<Selector xpath="//ol[@class='page-navigator']//@href" data='http://lab.scrapyd
.cn/page/1/'>,
<Selector xpath="//ol[@class='page-navigator']//@href" data='http://lab.scrapyd
.cn/page/2/'>,
<Selector xpath="//ol[@class='page-navigator']//@href" data='http://lab.scrapyd
.cn/page/3/'>,
<Selector xpath="//ol[@class='page-navigator']//@href" data='http://lab.scrapyd
.cn/page/4/'>,
<Selector xpath="//ol[@class='page-navigator']//@href" data='http://lab.scrapyd
.cn/page/6/'>,
<Selector xpath="//ol[@class='page-navigator']//@href" data='http://lab.scrapyd
.cn/page/2/'>]
可以看到也是同样得到想要的效果,以此类推,诸位根据自己的情况来缩小范围,如果这里的属性是id那就:ol[@id=’page-navigator’],灵活点!那这里我们还没有得出href,前后都有些括号,和css选择器一样我们还是用到了:extract()、extract_first()这两个函数,加上就可以提取纯粹的href值了,如下:
In [11]: response.xpath("//ol[@class='page-navigator']//@href").extract()
Out[11]:
['http://lab.scrapyd.cn/page/1/',
'http://lab.scrapyd.cn/page/2/',
'http://lab.scrapyd.cn/page/3/',
'http://lab.scrapyd.cn/page/4/',
'http://lab.scrapyd.cn/page/6/',
'http://lab.scrapyd.cn/page/2/']
好了,这就是属性的提取,表达式就是://@属性名 这里的话我们还给诸君说了另外一些思路,也就是:如何缩小范围?我们使用的是:缩小标签范围、限定属性的方式,希望诸君学到的是思路!
二、接下来我们提取标签里面的内容,表达式: //text()
这个没多少好讲的,关键是以上的思路,我们需要层次限制,把范围缩小到最小,这样提取便很准确了,诸位需要在实践中多练习,我们来提取一下:lab.scrapy.cn 的标题,看用法:
In [4]: response.xpath("//title//text()").extract()
Out[4]: ['SCRAPY爬虫实验室 - SCRAPY中文网提供']
可以看到,表达式为://title//text() ,就是用到了://text() 这个表达式,前面的://title是限定你要提取的范围,同理如果你要提取首页右侧的标签,如下:
<ul class="tags-list">
<li><a style="color:rgb(101,86,
72)" href="http://lab.scrapyd.cn/tag/%E4%BA%BA%E7%94%9F/">
人生</a></li>
<li><a style="color:rgb(214,236,
5)" href="http://lab.scrapyd.cn/tag/%E5%8A%B1%E5%BF%97/">
励志</a></li>
……
<li><a style="color:rgb(4,4,
41)" href="http://lab.scrapyd.cn/tag/%E7%BB%9D%E4%B8%96%E5%A5%BD%E8%AF%8D/">
绝世好词</a></li>
<li><a style="color:rgb(204,12,
225)" href="http://lab.scrapyd.cn/tag/%E6%9C%A8%E5%BF%83/">
木心</a></li>
……
<li><a href="http://lab.scrapyd.cn">返回首页</a></li>
<li><a href="http://bbs.scrapyd.cn" target="_blank">SCRAPY中文社区</a></li>
<li><a href="http://www.scrapyd.cn" target="_blank">SCRAPY中文网</a></li>
</ul>
可以看到标签文字是在 “class=tags-list” 的<ul>里面,那我们就可以这样写表达式://ul[@class=’tags-list’]//a//text(),具体代码如下:
In [5]: response.xpath("//ul[@class='tags-list']//a//text()").extract()
Out[5]:
['\r\n 人生',
'\r\n 励志',
'\r\n 爱情',
'\r\n 王尔德',
'\r\n 智慧',
'\r\n 泰戈尔',
'\r\n 绝世好词',
'\r\n 木心',
'\r\n 艺术',
'\r\n 名画',
'\r\n 生活',
'\r\n 词',
'返回首页',
'SCRAPY中文社区',
'SCRAPY中文网']
可以看到经过这样的限制,我们就定位到了;
三、包含HTML标签的所有文字内容提取:string()
这种用法主要是提取一些内容页,里面标签夹杂着文字,但我们只要文字!比如我们随便点击进:http://lab.scrapyd.cn/archives/28.html 这个详情页,我们要提取div里面的所有文字:
<div class="post-content" itemprop="articleBody">
<p>如果你因失去了太阳而流泪,那么你也将失去群星了。
<br>If you shed tears when you miss the sun, you also miss the stars.
</p>
<p><a href="http://www.scrapyd.cn">scrapy中文网(</a><a href="http://www.scrapyd.cn">http://www.scrapyd.cn</a>)整理</p>
</div>
如果我们用表达式://div[@class=’post-content’]//text(),你会发现虽然能提取但是一个列表,不是整段文字:
In [4]: response.xpath("//div[@class='post-content']//text()").extract()
Out[4]:
['\n ',
'如果你因失去了太阳而流泪,那么你也将失去群星了。 ',
'If you shed tears when you miss the sun, you also miss the stars. ',
'scrapy中文网(',
'http://www.scrapyd.cn',
')整理',
' ']
那这里我们就用到一个xpath函数:string(),我们可以把表达式这样写:response.xpath(“string(//div[@class=’post-content’])“).extract(),可看到我们没有使用:text(),而是用:string(要提取内容的标签),这样的话就能把数据都提取出来了,而且都合成为一条,并非一个列表,如下:
In [5]: response.xpath("string(//div[@class='post-content'])").extract()
Out[5]: ['\n 如果你因失去了太阳而流泪,那么你也将失去群星了。 If you
shed tears when you miss the sun, you also miss the stars. scrapy中文网(http://
www.scrapyd.cn)整理 ']
这一种用法在我们提取商品详情、小说内容的时候经常用到,望诸君好好学习、天天赚钱!
四、xpath实例:


XPath 通配符可用来选取未知的 HTML元素。

在下面的表格中,我们列出了一些路径表达式,以及这些表达式的结果:

差不多就这些,如果诸君还想深入,百度xpath有很多教程,我也懒得复制粘贴了,以上内容scrapy够用即可!
转载请注明:www.ainoob.cn » Scrapy Xpath






