机器学习包括监督学习、非监督学习、半监督学习及强化学习,这里先讨论监督学习。
监督学习的任务是学习一个模型,使模型能够对任意给定的输入,对其相应的输出做出一个好的预测。
1 基本概念
1.1 输入空间、特征空间与输出空间
输入与输出所有可能取值的集合分别称为输入空间与输出空间。
每个具体的输入是一个实例(instance),通常由特征向量(feature vector)表示,这时,所有特征向量存在的空间称为特征空间。特征空间的每一维对应于一个特征。有时假设输入空间与特征空间为相同的空间。有时假设为不同的空间,这里需要将输入空间映射于特征空间,这一过程称为特征提取。模型实际上都是定义在特征空间上的。在监督学习中,往往把输入空间看为特征空间。通常用x表示输入空间的一个实例

其中,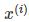 表示x的第i个特征。注意区分与Xi,前者是一个实例中的第i维特征的值,而后者表示一个训练集中的第i个实例,它是一个向量。
表示x的第i个特征。注意区分与Xi,前者是一个实例中的第i维特征的值,而后者表示一个训练集中的第i个实例,它是一个向量。
监督学习从训练数据集合中学习模型,对测试数据进行预测。训练数据由输入(或特征向量)与输出对组成,训练集通常表示为:
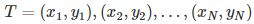
测试数据也是由相应的输入与输出对组成。
输入与输出变量均为连续变量的预测问题称为回归问题。输出变量为有限个离散变量的预测称为分类问题;输入变量与输出变量均为变量序列的预测问题称为标注问题。
1.2 联合概率分布
监督学习假设输入与输出的随机变量XX和Y遵循联合概率分布P(X,Y)P(X,Y)。训练数据与测试数据被看作是依联合概率分布P(X,Y)P(X,Y)独立同分布产生的。
对于要统计分析的数据,存在这样的联合概率分布P(X,Y)P(X,Y),这是监督学习对数据的基本假设。
1.3 假设空间
监督学习的目的在于学习一个输入到输出的映射,这一映射由模型来表示。但这样的映射往往不止一个,学习的目标在于找到最好的这样的模型。由这样的模型构成的集合就是假设空间。
监督学习的模型可以是概率模型或非概率模型。由条件概率分布P(Y|X)或决策函数Y=f(X)Y=f(X)表示。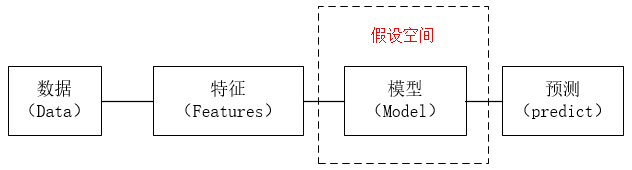
2 监督问题的形式化表示
监督学习利用训练数据集学习一个模型,再用模型对测试样本集进行预测。由于在这个过程中需要训练数据集,而训练数据集往往是人工给出的,所以称为监督学习。
监督学习分为学习和预测两个过程,由学习系统与预测系统完成,可以描述为下图。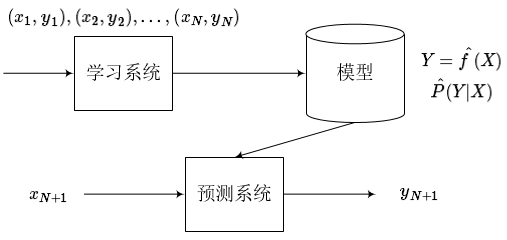
首先给定一个训练数据集: 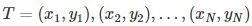
其中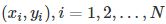 ,称为样本或样本点。Xi为一个输入的观测值,Yi为输出的观测值。
,称为样本或样本点。Xi为一个输入的观测值,Yi为输出的观测值。
监督学习中,假设训练数据与测试数据是依联合概率分布
独立同分布产生的。
在学习的过程中,学习系统利用给定的训练数据集,通过学习得到一个模型,表示为条件概率分布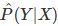 或决策函数
或决策函数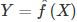 。
。
在预测过程中,预测系统对给定的测试样本集中的输入 ,由模型
,由模型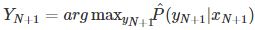 或
或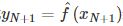 给出相应的输出
给出相应的输出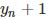 在学习的过程中,每一个
在学习的过程中,每一个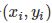 都会给模型带来一些信息,具体地说就是,对于输入
都会给模型带来一些信息,具体地说就是,对于输入
xi,一个具体的模型y=f(x)会产生一个输出 ,然后用与训练样本的输出yi对比,然后学习模型会根据这个差距适当的自我调整,以保证下次再遇到xi这个输入时,预测的比现在好。
,然后用与训练样本的输出yi对比,然后学习模型会根据这个差距适当的自我调整,以保证下次再遇到xi这个输入时,预测的比现在好。
转载请注明:www.ainoob.cn » 机器学习之监督学习






