1. 训练误差与测试误差
机器学习的目的是使学习到的模型不仅对已知数据而且对未知数据都能有很好的预测能力。
假设学习到的模型是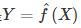 ,训练误差是模型关于训练数据集的平均损失:
,训练误差是模型关于训练数据集的平均损失:

其中NN是训练样本容量。
测试误差是模型关于测试数据集的平均损失:
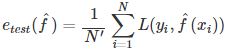
其中N′是测试样本容量。
当损失函数是0-1损失时,测试误差就变成了常见的测试数据集上的误差率(预测错误的个数除以测试数据的总个数)。
训练误差的大小,对判定给定问题是不是一个容易学习的问题是有意义的,但本质上不重要。测试误差反映了学习方法对未知数据集的预测能力,是学习中的重要概念。显然,给定两种学习方法,测试误差小的方法具有更好的预测能力,是更有效的方法。通常将学习方法对未知数据的预测能力称为泛化能力(generalization ability)。
2. 过拟合与模型选择
我们知道假设空间理论上有无限个模型,它们有着不同的复杂度(一般表现为参数个数的多少),我们希望选择或学习一个合适的模型。
如果一味提高对训练数据的预测能力,所选的模型的复杂度则往往会比真实模型更高。这种现象称为过拟合。过拟合是指学习时选择的模型所包含的参数过多,以致于出现这一模型对已知数据预测很好,但对未知数据预测很差的现象。
下面,以多项式函数拟合问题为例,说明过拟合与模型选择,这是一个回归问题。
现在给定一个训练数据集:
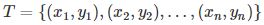
其中,Xi∈R是输入X的观测值,Yi∈R是相应的输出y的观测值。多项式函数拟合的任务是假设给定数据由M次多项式函数生成,选择最有可能产生这些数据的M次多项式函数,即在M次多项式函数中选择一个对已知数据以及未知数据都有很多预测能力的函数。
设M次多项式为:
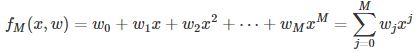
对于上面这个问题,模型的复杂度即为多项式的次数;然后在给定的模型复杂度下,按照经验风险最小化策略,求解参数,即多项式的系数,具体地,求以下经验风险最小化:
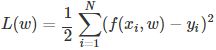
这时,损失函数为平方损失,系数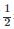 是为了计算方便。
是为了计算方便。
我们用y=sin(x)生成10个数据点,并适当的在y值上加了一些误差,下面我们分别用0~9次多项式对数据进行拟合。
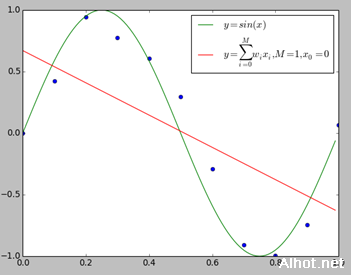
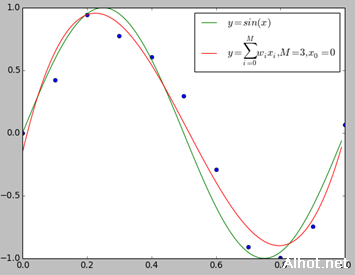
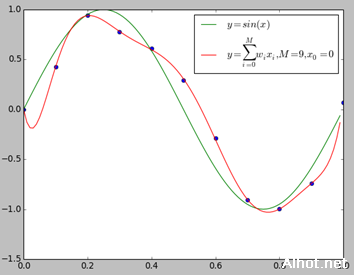
上图给出了M=1,M=3,M=9时多项式拟合的情况。当M=1时多项式曲线是一条直线,数据拟合效果很差。相反,如果M=9,多项式曲线通过每个数据点,训练误差为0。从对给定的训练数据拟合的角度来说,效果是最好的。但是因为训练数据本身存在噪声,这种拟合曲线对未知数据的预测能力往往并不是最好的,这时过拟合现象就会发生。
import numpy as np
import matplotlib.pyplot as plt
import random
x = np.linspace(0,1,10)
y = np.sin(2*np.pi*x)
for i in range(0,10):
y[i] = y[i] + random.uniform(-0.4,0.4)
p = np.polyfit(x,y,9)
t = np.linspace(0,1.0,100)
plt.plot(x,y,’o’)
plt.plot(t,np.sin(np.pi*2*t),label=’$y=sin(x)$’);
plt.plot(t,np.polyval(p,t),label=’$y = \sum_{i=0}^Mw_ix_i,M=9,x_0=0$’);
plt.legend()
plt.show()
3. 正则化与交叉验证
3.1 正则化
前面文章在介绍机器学习策略的时候,已经提到过结构风险最小化的概念。结构风险最小化正是为了解决过拟合问题来提出来的策略,它在经验风险上加一个正则化项。正则化项一般是模型复杂度的单调递增函数,模型越复杂,正则化值就越大。比如,正则化项可以是模型参数的向量的范数。
正则化项可以取不同的形式。例如,回归问题中,损失函数是平方损失,正则化项可以是参数向量的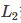 范数:
范数:
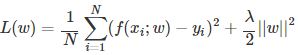
这里,||w||表示参数向量w的范数。
正则化项也可以是参数向量的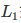 范数:
范数:
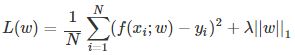
这里,||w||1|表示参数向量w的范数。
正则化符合奥卡姆剃刀(Occam’s razor)原理。奥卡姆剃刀应用在模型选择时想法是:在所有可能选择的模型中,能够很好地解释已知数据并且十分简单才是最好的模型,也就是应该选择的模型。从贝叶斯估计的角度来看,正则化项对应于模型的先验概率。可以假设复杂模型有较小的先验概率,简单的模型有较大的先验概率。
3.2 交叉验证
如果给定的样本数据充足,进行模型选择的一种简单方法是随机地将数据集切分成三部分,分别为训练集、验证集和测试集。训练集用来训练模型,验证集用于模型的选择,而测试集用于最终对学习方法的评估。在学习到的不同复杂度的模型中,选择对验证集有最小预测误差的模型。
但是在许多实际应用中数据是不充分的。为了选择好的模型,可以采用交叉验证方法。交叉验证的基本想法是重复地使用数据;把给定的数据进行切分,将切分的数据集组合为训练集与测试集,在此基础上反复地进行训练、测试以及模型选择。
1. 简单交叉验证
首先随机地将已给数据分为两部分,一部分作为训练集,另一部分作为测试集;然后用训练集在各种条件下训练模型,从而得到不同的模型;在测试集上评价各个模型的测试误差,选出测试误差最小的模型。
2. S折交叉验证
这种方法应用最多。首先随机地将已给的数据切分为S个互不相交的大小相同的子集;然后利用其中的S-1个子集的数据训练模型,然后用余下的子集测试模型;将这一过程对可能的S种选择重复进行;最后选出S次评测中平均测试误差最小的模型。
3. 留一交叉验证
S折交叉验证的特征情形是S=N,称为留一交叉验证,往往在数据缺乏的情况下使用。这里,N是给定数据集的容量。
4. 泛化能力
学习方法的泛化能力是指由该方法学习到的模型对未知数据的预测能力,是学习方法本质上重要的性质。现实中采用最多的办法是通过测试数据集的误差来评价学习方法的泛化能力。但是因为数据是有限的,并不能代表全体未知样本,所以很有可能按照这样评价到得的结果是不可靠的。
下面我们从理论上对学习方法的泛化能力进行分析。
首先给出泛化误差的定义。如果学习到的模型是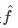 ,那么用这个模型对未知数据预测的误差即为泛化误差(generalization error)
,那么用这个模型对未知数据预测的误差即为泛化误差(generalization error)
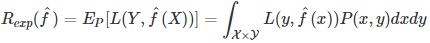
泛化误差反映了学习方法的泛化能力,如果一种方法学习的模型比另一种方法学习的模型具有更小的泛化误差,那么这种方法就更有效。事实上,泛化误差就是所学习到的模型的期望风险。
而我们知道数据的联合分布函数我们是不知道的,所以实际中,学习方法的泛化能力分析往往是通过研究泛化误差的概率上界进行的,简称泛化误差上界(generalization error bound)。具体来说,就是通过比较两种学习方法的泛化误差上界的大小来比较它们的优劣。
对二分类问题,当假设空间有有限个函数的集合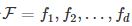 时,对任意一个函数f∈F,至少以概率
时,对任意一个函数f∈F,至少以概率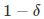 ,以下不等式成立:
,以下不等式成立:
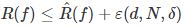
其中,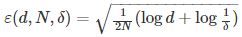
不等式左边R(f)是泛化误差,右端即为泛化误差的上界。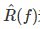 为训练误差。
为训练误差。
转载请注明:www.ainoob.cn » 机器学习的模型评估与模型选择






