随着我对机器学习的了解的增加,机器学习算法的数量也在增加! 本文将介绍数据科学界常用的机器学习算法。

请记住,我将比其他更多地详细阐述某些算法,因为如果我对每种算法进行了详尽的解释,那么本文将与本书一样长!我还将尝试尽量减少本文中的数学运算量,因为我知道这对于那些数学上不精通的人来说可能是令人生畏的。相反,我将尝试对每个功能进行简要概述,并指出一些关键功能。
考虑到这一点,我将首先介绍一些更基本的算法,然后再介绍一些较新的算法,例如CatBoost,Gradient Boost和XGBoost。
线性回归
线性回归是用于对因变量和一个或多个自变量之间的关系进行建模的最基本算法之一。简而言之,它涉及找到代表两个或多个变量的”最佳拟合线”。
最佳拟合线是通过最小化点与最佳拟合线之间的平方距离来找到的-这称为最小化残差平方和。残差等于预测值减去实际值。
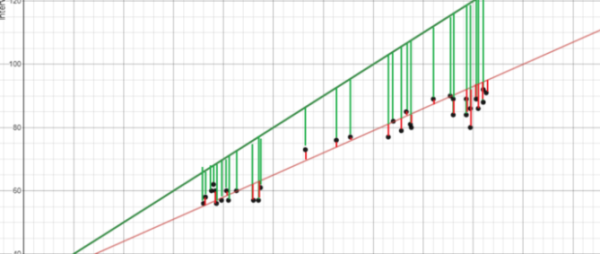
> Image Created by Author
如果还没有意义,请考虑上面的图片。 将最适合的绿线与红线进行比较,请注意,绿线的垂直线(残差)比红线大得多。 这是有道理的,因为绿线离这些点太远了,根本就不能很好地表示数据!
如果您想了解有关线性回归背后的数学知识的更多信息,那么我将从Brilliant的解释开始。
逻辑回归
Logistic回归与线性回归相似,但用于建模离散结果数(通常为两个)的概率。 乍一看,逻辑回归听起来比线性回归复杂得多,但实际上只需要多做一步。
首先,您使用与最适合线性回归的直线方程式相似的方程式计算得分。
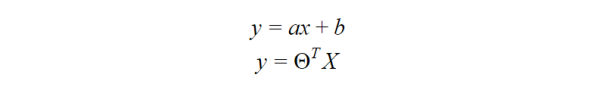
额外的步骤是将您先前在下面的S型函数中计算出的分数提供给您,以便您获得回报的可能性。然后可以将此概率转换为二进制输出,即1或0。
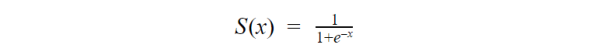
为了找到初始方程的权重以计算分数,使用了诸如梯度下降或最大似然法之类的方法。 由于它不在本文的讨论范围之内,所以我将不做进一步的详细介绍,但是现在您知道了它的工作原理!
K最近邻居
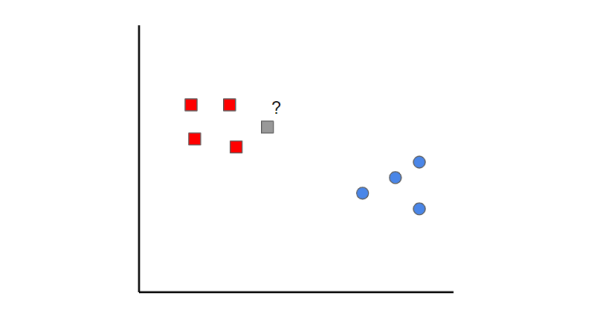
> Image created by author
K近邻是一个简单的想法。首先,从已分类的数据(即红色和蓝色数据点)开始。然后,当您添加新数据点时,可以通过查看k个最近的分类点对其进行分类。得票最多的哪个类别决定将新点分类为什么。
在这种情况下,如果将k设置为1,则可以看到与灰色样本最接近的第一个点是红色数据点。 因此,该点将被分类为红色。
要记住的一点是,如果k的值设置得太低,可能会导致异常值。另一方面,如果k的值设置得太高,那么它可能会忽略只有几个样本的类。
朴素贝叶斯
朴素贝叶斯是一种分类算法。 这意味着当输出变量为离散变量时,将使用朴素贝叶斯。
朴素贝叶斯(Naive Bayes)似乎是一个令人生畏的算法,因为它需要具备条件概率和贝叶斯定理的初步数学知识,但这是一个非常简单且”朴素”的概念,我将尽力举例说明:
> Image Created by Author
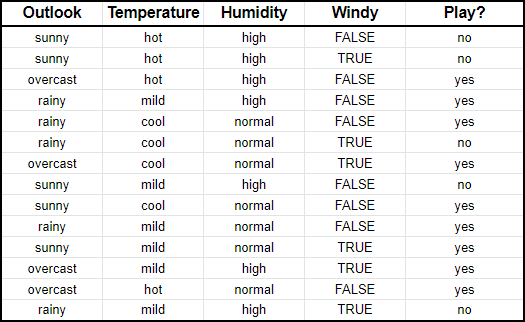
假设我们输入了有关天气特征(外观,温度,湿度,大风)以及是否打过高尔夫球的数据(即最后一栏)。
朴素贝叶斯本质上所做的是比较每个输入变量与输出变量中类别之间的比例。可以在下表中显示。

> Image Created by Author
为了帮助您阅读本示例,在温度部分中,打高尔夫球的9天中有2天很热(即是)。
用数学术语,您可以将其表示为打高尔夫球时很热的概率。数学符号为P(hot | yes)。这就是条件概率,对于理解我将要说的其余内容至关重要。
掌握了这些信息后,您就可以根据天气特征的任意组合预测是否要打高尔夫球。
想象一下,我们具有以下特征的新一天:
- 展望:晴天
- 温度:温和
- 湿度:正常
- 大风:假
首先,我们将计算在给定X,P(y | X)的情况下打高尔夫球的概率,然后计算在给定X,P(no | X)的情况下您打高尔夫球的概率。
使用上面的图表,我们可以获得以下信息:

现在我们可以简单地将此信息输入以下公式:
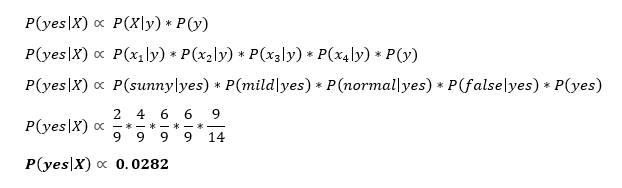
同样,您将为P(no | X)完成相同的步骤顺序。

由于P(yes | X)> P(no | X),因此您可以预测此人会打高尔夫球,因为前景晴朗,温度适中,湿度正常且没有大风。
这是朴素贝叶斯的精髓!
支持向量机
> Image created by Author
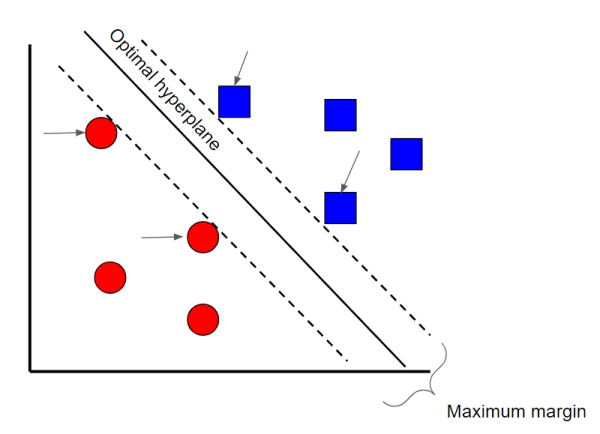
支持向量机是一种监督分类技术,实际上可能会变得非常复杂,但在最基本的级别上却非常直观。 为了本文的方便,我们将其保持在较高水平。
假设有两类数据。 支持向量机将在两类数据之间找到一个超平面或边界,以使两类数据之间的余量最大化(请参见上文)。 有许多平面可以将两个类别分开,但是只有一个平面可以使两个类别之间的边距或距离最大化。
如果您想了解支持向量机背后的数学知识,请查看此系列文章。
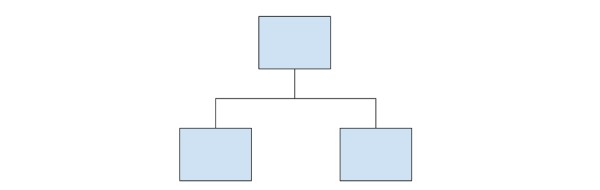
决策树

> Image created by author
随机森林
在理解随机森林之前,您需要了解以下两个术语:
- 集成学习是一种结合使用多种学习算法的方法。这样做的目的是,与单独使用单个算法相比,它可以实现更高的预测性能。
- 自举采样是一种重采样方法,该方法使用随机采样进行替换。 听起来很复杂,但是当我说它非常简单时,请相信我-在此处了解更多信息。
- 当您使用自举数据集的汇总来做决定时,请进行装袋–我在该主题上撰写了一篇文章,因此,如果这样做不完全有意义,请随时在此处查看。
现在您已经了解了这些术语,让我们深入研究它。
随机森林是一种基于决策树的整体学习技术。 随机森林涉及使用原始数据的自举数据集创建多个决策树,并在决策树的每个步骤中随机选择变量的子集。 然后,模型选择每个决策树的所有预测的模式(装袋)。 这有什么意义? 通过依靠”多数胜利”模型,它降低了单个树出错的风险。

> Image Created by author
例如,如果我们创建一个决策树,第三个决策树,它将预测0。但是,如果我们依靠所有4个决策树的模式,则预测值为1。这就是随机森林的力量!
AdaBoost
AdaBoost或Adaptive Boost也是一种集成算法,它利用打包和增强方法来开发增强的预测器。
AdaBoost与Random Forests的相似之处在于,预测来自许多决策树。但是,AdaBoost的独特之处在于三个主要区别:
> Example of a stump
- 首先,AdaBoost创建了一个由树桩而非树木组成的森林。树桩是仅由一个节点和两片叶子组成的树(如上图所示)。
- 其次,在最终决策(最终预测)中未对创建的树桩加权平均。产生更多错误的树桩在最终决定中将没有发言权。
- 最后,树桩的制作顺序很重要,因为每个树桩的目的都是减少先前树桩造成的错误。
从本质上讲,AdaBoost采取了一种更具迭代性的方法,即从以前的树桩所犯的错误中寻求迭代地改进。
如果您想了解有关AdaBoost背后的基础数学的更多信息,请查看我的文章” 5分钟内AdaBoost的数学解释”。
梯度提升
渐变增强也是一种集成算法,使用增强方法来开发增强型预测因子也就不足为奇了。在许多方面,Gradient Boost与AdaBoost相似,但有两个主要区别:
- 与AdaBoost可以构建树桩不同,Gradient Boost可以构建通常具有8–32片叶子的树木。
- 梯度增强将增强问题视为优化问题,它使用损失函数并尝试将误差最小化。 这就是为什么它受梯度下降的启发而称为”梯度增强”的原因。
- 最后,这些树用于预测样本的残差(预测值减去实际值)。
尽管最后一点可能令人困惑,但您需要知道的是,Gradient Boost首先要构建一棵树以尝试拟合数据,而随后构建的树则旨在减少残差(错误)。它通过专注于现有学习者表现较差的领域来做到这一点,类似于AdaBoost。
XGBoost
XGBoost是当今最流行和使用最广泛的算法之一,因为它是如此强大。它类似于Gradient Boost,但具有一些使其更强大的额外功能,包括……
- 叶节点按比例缩小(修剪)—用于改善模型的泛化
- 牛顿加速-提供比梯度下降更直接的最小值,使其更快
- 额外的随机化参数-减少树之间的相关性,最终提高整体强度
- 树木的独特惩罚
我强烈建议您观看StatQuest的视频,以更详细地了解算法的工作原理。
LightGBM
如果您认为XGBoost是目前最好的算法,请再考虑一下。 LightGBM是另一种增强算法,已显示出比XGBoost更快甚至更高的准确性。
LightGBM的与众不同之处在于,它使用一种称为基于梯度的单面采样(GOSS)的独特技术来过滤出数据实例以查找分割值。这与XGBoost不同,后者使用预排序和基于直方图的算法来找到最佳分割。
在这里阅读更多关于Light GBM vs XGBoost的信息!
CatBoost
CatBoost是基于梯度下降的另一种算法,具有一些细微的差异,使其独特:
- CatBoost实现对称树,这有助于减少预测时间,并且默认情况下树深度也较浅(六个)
- CatBoost利用类似于XGBoost具有随机参数的方式的随机排列
- 但是,与XGBoost不同,CatBoost使用有序增强和响应编码等概念更优雅地处理分类功能
总体而言,使CatBoost如此强大的原因是其低延迟要求,这意味着它比XGBoost快大约八倍。
如果您想更详细地了解CatBoost,请查阅本文。
谢谢阅读!
如果您成功了,那就恭喜!现在,您应该对所有不同的机器学习算法有了更好的了解。
如果您很难理解最后几种算法,不要灰心–它们不仅更复杂,而且相对较新!因此,请继续关注更多资源,这些资源将更深入地应用于这些算法。
作者:闻数起舞_今日头条
原文链接:https://www.toutiao.com/i6897837615106605571/
转载请注明:www.ainoob.cn » 2021年码农应该了解的所有机器学习算法






