本文转载自公众号“读芯术”(ID:AI_Discovery)。
近几年来,机器学习飞速发展,开展机器学习试验变成小事一桩。有了scikit-learn和Keras这样的资源库,只需几行代码,就能创建模型。
然而,把数据科学项目转变成有意义的应用程序(比如公告团队决策或融入产品的模型)却愈加困难。传统的机器学习项目涉及许多不同的技能组合,想同时掌握全部技能,即便不是绝无可能也绝非易事——那些罕见的既能开发优质软件,又能做工程师的数据科学家即为独角兽!
机器学习领域愈加成熟,许多工作都将融合软件、工程和数学知识,一些工作已然如此了。
引用传奇数据科学家、工程师、批判观察家Vicki Boykis博客《数据科学现已不同》中的话:“在热潮后期,数据科学渐渐与工程学靠拢。显而易见的是,数据科学家所需技能的可视性将减弱、数据依赖性将降低,且会愈加偏向传统计算机科学课程。”

为什么数据科学家需要了解DevOps
有那么多工程和软件技能,数据科学家应该学习什么呢?我选DevOps。
DevOps是开发和运营的合称,它于2009年在比利时的一场会议中诞生。该会议旨在缓解技术组织中开发、运营因长期的巨大分歧而产生的紧张态势。软件开发人员需要快速产出、频繁试验,而运营团队则优先考虑服务的稳定性及可用性(这群人让服务器全天候运转)。其目标对立,彼此之间更是竞争关系。
这不禁令人想到当下的数据科学。通过实验,数据科学家创造价值:用新方式建模、组合、转换数据。同时,聘用数据科学家的技术组织更看重稳定性。
这种分歧波及范围广泛:最新的Anaconda数据科学状况报告显示,认为自己能诠释数据科学对其组织影响的受访者不足一半(48%)。据估计,数据科学家创建的模型大多被束之高阁。我们目前没有十分可行的方式,能在建模团队及部署团队间传递模型。数据科学家、开发者及落实二者工作的工程师有着截然不同的工具、限制及技能。
DevOps的出现旨在解决开发者和运营者之间的软件僵局,并取得了极大成功:许多团队部署新代码的频率从数月一次变为一天数次。现在面对的是机器学习和运营的对抗,MLOps这一为数据科学服务的DevOps原则闪亮登场。

图源:unsplash
持续集成
DevOps既是理论,又是实践,它包括:
- 自动化一切事物
- 快速获得新想法的反馈
- 减少工作流中的手动交接
在典型的数据科学项目中,存在如下应用:
- 自动化一切事物。重复且可预测的部分数据处理、模型训练及模型测试皆可自动化。
- 快速获得新想法的反馈。当数据、代码或软件环境发生变化时,在类生产环境下迅速对其进行测试(即,生产中有依赖项和限制的机器)。
- 减少工作流中的手动交接。尽可能为数据科学家找寻模型测试的机会,切勿等到开发人员在生产环境下检测模型效果再行动。
为实现以上目标,DevOps采用的标准是持续集成(continuous integration, CI)。关键在于,改变项目源代码时(一般是通过git commits更改),软件被自动创建并测试,每个行为都会得到反馈。通常,CI与创建新功能Git分支的软件开发活动模型Git-flow配合使用。功能分支通过自动测试便可候选并入主分支。
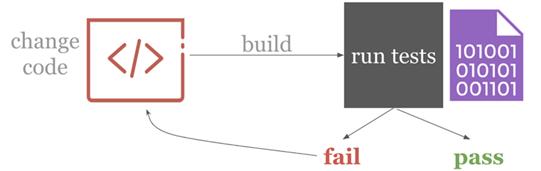
CI在软件开发过程中的示意图
由此即可实现自动化——改变代码触发自动构建,测试紧随其后。由于迅速得到测试结果,便可以得到快速反馈,因此,开发者能对代码进行反复迭代。并且,由于一切皆为自动,无需等待他人反馈,实现零切换。
所以,我们为什么不使用已存在于机器学习中的CI呢?我将部分归因于文化,比如数据科学与软件工程群体的低交叉性。
另一部分就是技术原因。比如,了解模型性能,需查看准确率、特异度和敏感度等指标。要了解模型的性能,就需要查看准确率、特异度和灵感度等指标。数据可视化(如混淆矩阵或损失图)或许会对此有所帮助。所以,测试通过/失败并不会阻碍反馈。若要了解模型是否得到改进,我们需要了解当前问题领域的知识,所以测试结果需要以高效且可人为诠释的方式报道。
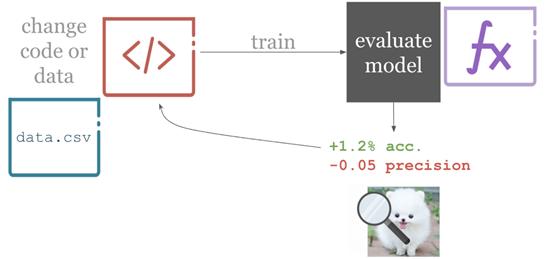
机器学习项目中的连续集成
持续集成系统如何运作?
现在,看看典型的CI系统如何运作。多亏了GitHub Actions和GitLab CI这类图像界面清晰且为新手提供详细操作文档的工具,学习CI系统的门槛降至最低。由于GitHub Actions对开源项目完全免费,我们就用它举例:
其运作方式如下:
(1) 建立一个GitHub仓库。创建名为.github/workflows的目录,在目录中放置一个特殊的.yaml文件,其中包含要运行的脚本,如:
- $ python train.py
(2) 更改项目库内文件,git commit更新,然后提交到GitHub库。
- # Create a new git branch for experimenting$ git checkout -b "experiment"
- $ edit train.py# git add, commit, and push your changes
- $ git add . && commit -m "Normalized features"
- $ git push origin experiment
(3) 检测到推送,GitHub立刻在其中一台计算机上运行.yaml文件的函数。
(4) GitHub弹出通知,是否成功运行函数。

在GitHub仓库的操作选项卡中找到以上内
就这么简单!只需更新代码,并把更新提交到数据库,工作流就自动执行。
回到第一步提到的特殊的.yaml文件——快速看一个。随意命名,文件后缀是.yaml即可,并将其储存在.github/workflows中。如:
- # .github/workflows/ci.yamlname: train-my-model
- on: [push]jobs:
- run:
- runs-on: [ubuntu-latest]
- steps:
- - uses: actions/checkout@v2
- - name: training
- run: |
- pip install -r requirements.txt
- python train.py
指令多如云,但大多数都是从一个Action到另一个Action——大可照搬这份GitHubActions指南,记得在“运行”段填写工作流就好。
若文件在项目库中,只要GitHub检测到代码更新(通过推送变更),GitHub Actions便会部署Ubuntu服务器,尝试执行安装需求的命令并运行Python脚本。请注意,项目仓库中必须有工作流程所需文件——在这里为requirements.txt和train.py!
得到更好的反馈
自动训练很酷,但对所有的结果来说,采用易于理解的格式也很重要。现在,GitHub Actions允许访问纯文本格式的服务器日志。
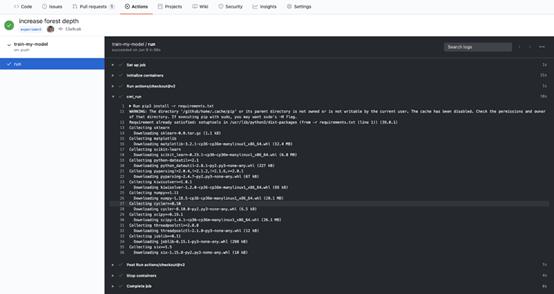
GitHub Actions日志的打印输出示例
但了解模型性能是个棘手的活儿。模型和数据都是高维且非线性的——若无图片,了解这二者太难了。
我可以展示一种将数据可视化放入CI循环的方法。近几个月,我在Iterative.ai的团队(做数据版本控制)一直在研究工具包,助力GitHub Actions和GitLab CI在机器学习项目中的使用,称为持续机器学习(Continuous Machine Learning ,简称CML)。这是开源且免费的。
团队的基本理念是:“用GitHub Actions训练机器学习模型”。我们已经建立了一些函数,可给出更详细的报告而非一个成功/失败的通知。CML有助于在报告中放置图片和表格,如这个SciKit-learn生成的混淆矩阵:
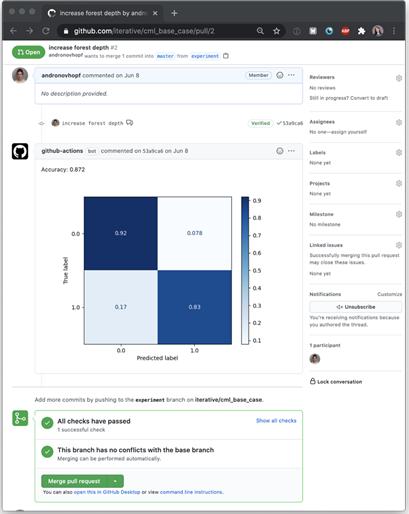
在GitHub中点Pull Request即显示此报告
为了制作报告,GitHub Actions执行Python模型训练脚本,用CML函数把模型准确率和混淆矩阵写入markdown文件。然后CML把markdown文件传到GitHub。
修改后的.yaml文件包含以下工作流(新添加的行以粗体突出显示)。
- name: train-my-model
- on: [push]
- jobs:
- run:
- runs-on: [ubuntu-latest]
- container: docker://dvcorg/cml-py3:latest
- steps:
- - uses: actions/checkout@v2
- - name: training
- env:
- repo_token: ${{secrets.GITHUB_TOKEN }}
- run: |
- # train.py outputs metrics.txtand confusion_matrix.png
- pip3 install -rrequirements.txt
- python train.py
- # copy the contents ofmetrics.txt to our markdown report
- cat metrics.txt >>report.md # addour confusion matrix to report.md
- cml-publishconfusion_matrix.png --md >> report.md # send the report to GitHub fordisplay
- cml-send-comment report.md
记住,.yaml现在包含更多详细配置信息,例如特殊的Docker容器和环境变量,以及一些要运行的新代码。每个CML项目中的容器及环境变量的详细信息都是固定的,用户无需操作,只关注代码就行。
将这些CML函数添加到工作流中,我们便在CI系统中创建了更完整的反馈循环:
- 建立一个Git分支,在分支上更新代码。
- 自动训练模型并生成度量(准确率)和可视化(混淆矩阵)。
- 将这些结果嵌入到Pull Request中的可视报告。
当你和队友还在考虑更新是否有助于实现建模目标时,各种可参照的可视化表盘就已经新鲜出炉了。另外,该报告通过Git连接到确切项目版本(数据和代码)、训练所用服务器及服务器的日志。无比详细!工作空间不再总是漂浮着与代码无关的图表了。
这就是CI在数据科学项目中的基本概念。明确一下,这只是使用CI的最简单的实例。实际操作中很可能遇到各种更为复杂的情况。CML也有一些特性,可帮你使用储存在GitHub库之外的大数据集(使用DVC)并在云端进行训练,而非在默认的GitHub Actions服务器训练。这意味着能使用GPU和其它专业设置。
例如,我用GitHub Actions创建一个项目以部署EC2 GPU,然后训练神经风格转换模型。这是我的CML报告:
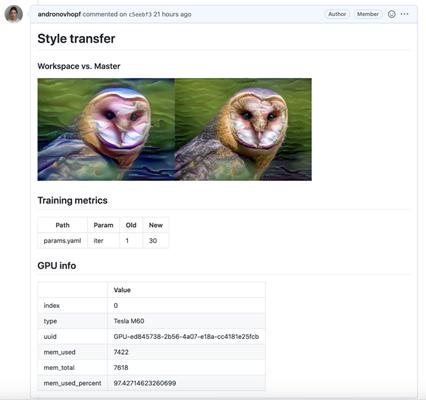
还可使用自己的Docker容器,进一步模拟
CI对机器学习的最后思考
总结一下,DevOps不是一种特定技术。它既是理论,又是一系列原则和实践,用于彻底重建开发软件过程,其高效性在于解决了团队工作及测试新代码的系统性瓶颈。
未来,数据科学愈加成熟,掌握在机器学习项目中运用DevOps原则的人就更加炙手可热——薪资可观,组织影响力大。持续集成是DevOps的基础,也是已知的建立具有可靠自动化、快速测试和团队自治文化的最有效方法之一。
GitHub Actions或GitLab CI之类的系统可实现CI。可使用这些服务构建自动模型训练系统。其益处颇多:
- 代码、数据、模型和训练基础(硬软件环境)都是git版本。
- 自动化工作、进行高频测试并得到迅速反馈(使用CML即可拿到可视化报告)。从长期看,这无疑会加速项目发展。
- CI系统让每个团队成员都能看到工作进展。大家无需绞尽脑汁搜集最佳运行的代码、数据及模型。

图源:unsplash
一旦入了坑,一键git commit就能自动进行模型训练、记录并报告,绝对让你乐翻天。行动起来,感觉棒极了!

关注“51CTO技术栈”微信公众号获取更多精彩内容
 51CTO技术栈
51CTO技术栈作者:读芯术_今日头条
原文链接:https://www.toutiao.com/i6857528292510007822/







