许多人在赶上机器学习(ML)或人工智能(AI)时想象出机器人或终结者。 但是,它们并不是电影中没有的东西,只是优秀的梦想。 已经在这里了 尽管ML从业人员在从零开发应用程序到生产应用程序的过程中可能会遇到某些挑战,但我们正处在使用机器学习开发大量优秀应用程序的情况下。

这些挑战是什么? 让我们来看看!
1.数据收集
在任何用例中,数据都起着关键作用。 数据科学家的60%的工作在于收集数据。 为了让初学者尝试机器学习,他们可以轻松地从Kaggle,UCI ML Repository等中查找数据。
要实现实际案例,您需要通过网络抓取或(通过Twitter等API)收集数据,或者为解决业务问题而需要从客户端获取数据(此处ML工程师需要与领域专家协作以收集数据) 。
收集完数据后,我们需要对数据进行结构化并将其存储在数据库中。 这需要了解大数据(或数据工程师)的知识,而大数据在这里起着主要作用。
2.训练数据量少
收集完数据后,您需要验证数量是否足以满足用例的要求(如果是时间序列数据,我们至少需要3-5年的数据)。
在进行机器学习项目时,我们要做的两个重要事情是选择一种学习算法,并使用一些获取的数据来训练模型。 因此,作为人类,我们自然会犯错,结果可能会出错。 在这里,错误可能是选择了错误的模型或选择了错误的数据。 现在,我所说的不良数据是什么意思? 让我们尝试了解。
假设您的机器学习模型是婴儿,您计划教婴儿区分猫和狗。 因此,我们首先指着猫说”这是一只CAT”,然后对DOG做同样的事情(可能多次重复此过程)。 现在,孩子将能够通过识别形状,颜色或任何其他特征来区分猫和狗。 就这样,婴儿变成了天才(与众不同)!
以类似的方式,我们使用大量数据训练模型。 一个孩子可以用较少的样本数来区分动物,但是机器学习模型甚至需要针对简单问题的数千个例子。 对于诸如图像分类和语音识别之类的复杂问题,可能需要数以百万计的数据。
因此,一件事很清楚。 我们需要训练具有足够数据的模型。
3.非代表性训练数据
培训数据应代表新案例以更好地进行概括,即,我们用于培训的数据应涵盖所有发生的和即将发生的案例。 通过使用非代表性训练集,训练后的模型不太可能做出准确的预测。
开发用于在业务问题视图中对一般情况进行预测的系统被认为是很好的机器学习模型。 即使数据模型从未见过的数据,也将有助于模型表现良好。
如果训练样本的数量少,则我们的采样噪声是不具代表性的数据,如果用于训练的策略存在缺陷,那么无数的训练测试也会带来采样偏差。
1936年美国总统大选期间(兰登对罗斯福),发生了一个调查抽样偏见的流行案例,《文学文摘》进行了一次非常大的民意调查,向大约1000万人发送邮件,其中240万人回答了这一问题,并预测兰登 将以高度的信心获得57%的选票。 罗斯福以62%的选票获胜。
这里的问题在于抽样方法,用于获取进行民意测验的电子邮件地址,《文学文摘》使用过的杂志订阅,俱乐部会员名单等,这些钱一定会被富有的个人用来投票给共和党人(因此, 落在)。 此外,由于只有25%的受访者回答了无回应的偏见。
为了做出准确的预测而没有任何漂移,训练数据集必须具有代表性。
4.数据质量差
实际上,我们不会直接开始训练模型,分析数据是最重要的步骤。 但是我们收集的数据可能尚未准备好进行训练,例如某些样本异常,而另一些样本则具有异常值或缺失值。
在这些情况下,我们可以删除异常值,或者使用中位数或均值(以填充高度)填充缺失的特征/值,或者简单地删除具有缺失值的属性/实例,或者在有或没有这些实例的情况下训练模型。
我们不希望我们的系统做出错误的预测,对吧? 因此,数据质量对于获得准确的结果非常重要。 数据预处理需要通过过滤缺失值,提取和重新排列模型所需的内容来完成。
5.不相关/不需要的特征
垃圾进垃圾出
如果训练数据包含大量不相关的特征和足够的相关特征,则机器学习系统将不会给出预期的结果。 机器学习项目成功所需的重要方面之一是选择好的特征以训练模型,也称为特征选择。
假设我们正在一个项目中,根据我们收集的输入特征(年龄,性别,体重,身高和位置(即他/她的居住地))来预测一个人需要运动的小时数。
- 在这5特征中,位置值可能不会影响我们的输出特征。 这是不相关的功能,我们知道没有此功能可以得到更好的结果。
- 另外,我们可以将两个特征结合起来以产生更有用的一个特征,即特征提取。 在我们的示例中,我们可以通过消除体重和身高来产生一个称为BMI的功能。 我们也可以对数据集应用转换。
- 通过收集更多数据来创建新特征也有帮助。
6.过度拟合训练数据
假设您访问了新城市的一家餐馆。 您查看了菜单以订购商品,发现费用或账单过高。 您可能会想说”城市中的所有餐馆都太贵了,负担不起”。 过度概括是我们经常要做的事情,令人震惊的是,框架也可能陷入类似的陷阱,在AI中,我们称之为过拟合。
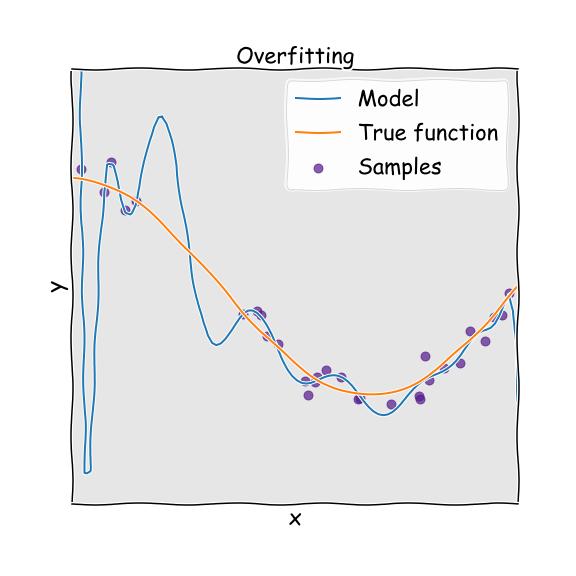
> Overfitting
这意味着该模型运行良好,可以对训练数据集进行预测,但不能很好地概括。
假设您正在尝试实施”图像分类”模型,分别对训练样本分别为3000、500、500和500的苹果,桃子,橘子和香蕉进行分类。 如果我们使用这些样本训练模型,则系统更可能将橘子分类为苹果,因为苹果的训练样本数量过多。 这可以称为过采样。
当模型与训练数据集的噪声相比过于不可预测时,就会出现过度拟合。 我们可以通过以下方法避免这种情况:
- 收集更多的训练数据。
- 选择具有较少特征的模型,与线性模型相比,较高阶多项式模型不是优选的。
- 修复数据错误,消除异常值,并减少训练集中的实例数量。
7.训练数据不足
当模型过于简单以至于无法理解数据的基本结构时,通常会发生与过度拟合相反的欠拟合。 这就像试图穿上小号裤子。 通常,当我们缺少用于构建精确模型的信息时,或者当我们尝试使用非线性信息来构建或开发线性模型时,就会发生这种情况。
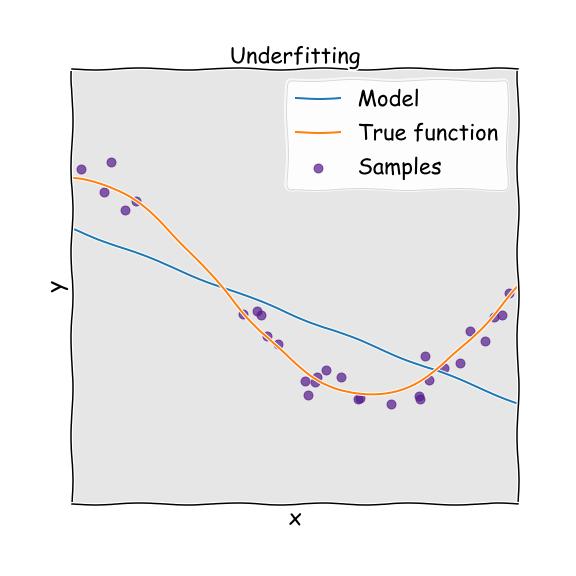
> Underfitting
减少欠拟合的主要选项是:
- 特征工程-为学习算法提供更好的特征。
- 消除数据中的噪音。
- 增加参数并选择功能强大的模型。
8.离线学习和部署模型
机器学习工程在构建应用程序时遵循以下步骤:1)数据收集2)数据清理3)功能工程4)分析模式5)训练模型和优化6)部署。
糟糕! 我说部署了吗? 是的,许多机器学习从业者可以执行所有步骤,但缺乏部署技能,由于缺乏实践和依赖关系问题,对业务基础模型的了解不足,将其出色的应用程序投入生产已成为最大的挑战之一, 了解业务问题,模型不稳定。
通常,许多开发人员从像Kaggle这样的网站收集数据并开始训练模型。 但实际上,我们需要为数据收集提供一个动态变化的源。 离线学习或批量学习不能用于这种类型的变量数据。 该系统经过培训,然后投入生产,无需学习即可运行。 由于动态变化,数据可能会漂移。
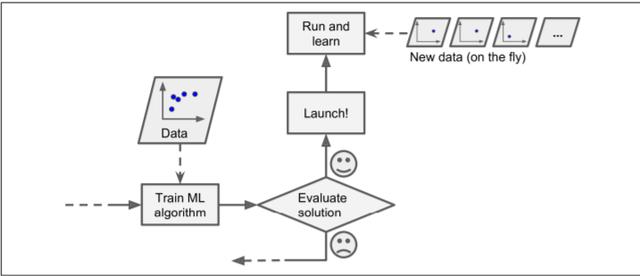
> Online Learning
始终首先建立一条管道来收集,分析,构建/训练,测试和验证任何机器学习项目的数据集,并分批训练模型。
结论
如果训练集太小,或者数据没有被泛化,嘈杂且具有不相关的功能,则系统将无法正常运行。 在练习机器学习时,我们经历了初学者面临的一些基本挑战。
如果您有任何建议,我将很高兴听到。 我很快会再提出另一个有趣的话题。 到那时,待在家里,保持安全并继续探索!
作者:闻数起舞_今日头条
原文链接:https://www.toutiao.com/i6849376669237674509/
转载请注明:www.ainoob.cn » 机器学习从业者面临的8大挑战






