即将开播:5月20日,基于kubernetes打造企业级私有云实践
机器学习是一种数据分析技术,可在数据集上构建预测模型,以提供有用的答案,这些答案可用于制定重要决策。 它利用统计概念和数学方法通过python和R等编码语言处理大数据。有多种机器学习技术。 但是,本文将介绍回归和分类。
回归
回归用于预测连续的数值数据。 它是一种广泛使用的统计概念,可以手动应用于具有两个变量和少量元素的小型数据集。 当处理具有多个变量和元素负载的大型数据集时,通过将包含数据集的文件上载到编码平台并运行一堆代码来完成回归。
有多种不同的回归技术,例如线性回归,多项式回归,多元线性回归和多元多项式回归。 它们的应用根据要使用多少个自变量来预测因变量而有所不同。 以下是一些与回归相关的有用术语:
回归方程
回归方程是使用自变量对因变量进行预测的方程。 可以表示为y = mx + b,y = ax ^ n + bx ^ n-1 +…+ c,y = ax + bx2 +…+ c或y = ax ^ n + bx ^ n-1 +…+ c分别表示线性回归,多项式回归,多元线性回归和多元多项式回归。
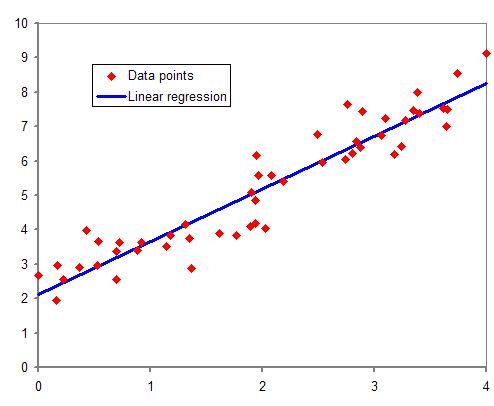
回归系数
回归系数是应用于线性回归或多元线性回归的常数值。 它可能对因变量产生增加或减少的影响。 让我们举一个例子,其中使用年龄和身高(cm)等变量来确定体重(磅)。
对于线性回归,可以将其表示为体重= 5 *年龄+30。此等式表明,年龄每增加1年,体重就会增加5磅。
对于多元线性回归,它可以表示为体重= 4 年龄+ 2.5 高度+30。该方程式意味着,假设年龄为零,则体重每增加1厘米将增加2.5幅度。 身高为零,体重将增加4磅,年龄会增加一年。
Y轴截距
如果将回归系数或x设置为零,则这可以描述为因变量的值。 可以表示为y = c。 这也是回归线切割y轴的点。
培训模型与测试模型
数据集分为两组:训练数据集和测试数据集。 将数据集分成几组后,使用训练数据集生成回归方程。 开发完成后,将回归方程应用于测试数据集以创建预测。
可以将预测值与实际值进行比较以测试准确性。 评估预测的指标如下:
测定系数
r平方的确定系数是一种有用的机制,用于解释回归方程对进行预测的准确性。 通过将预测值与实际值进行比较来完成此操作。 它提供了一个值,该值表示自变量解释了因变量的比例。 为了提高r平方得分,可以从一种回归样式切换到另一种回归样式。
相关系数
这是另一个非常有用的值,它描述了实际结果和预测结果中的值之间的关系。 范围是-1到1。如果相关系数为负,则预测结果会随着实际结果的减少而增加,反之亦然。 如果为正,则预测结果随实际结果的增加而增加。 值越接近| 1 |,关系就越完美。
均方根误差
均方误差是每个数据点的预测值和实际值之间的总平方差的平均值。 该值是数据集平均距离回归线的接近程度的度量。 该值的平方根称为均方根误差。 目的是使均方根误差接近0,以获得最佳拟合。
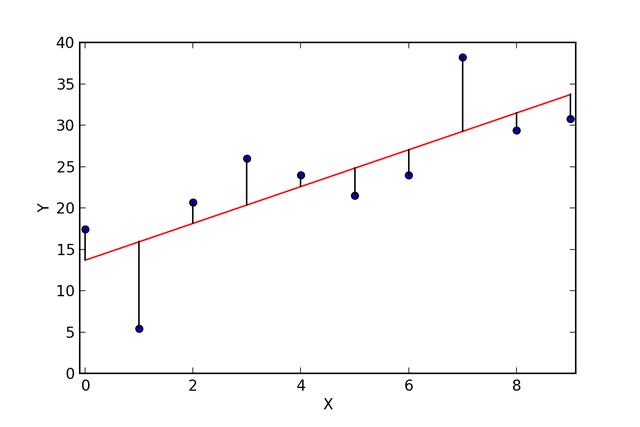
分类
分类是另一种很棒的机器学习算法,可用于预测分类数据集。 自变量可以是连续的或分类的,而因变量是分类的。 分类可以用来建立提供是(1)或否(0)答案的模型,也可以用来建立多个类别(0,1,2 ….),具体取决于用户的议程。 像回归一样,它利用训练和测试数据集。
使用我预测贷款申请状态的前一个项目的结果,下面将解释分类方法,例如K最近邻居和决策树分类器及其度量标准:
K最近邻居
这是一种分类方法,使用最接近该特定数据点的数据点来预测该数据点应属于的类别。 通过评估每个数据点的独立变量和因变量,并将它们与k个最接近的变量进行比较,它使用训练数据集创建了一个预测模型。 该模型用于预测测试数据集中每个数据点的类别,并测量其准确性。
通过将k设置为1来进行多次迭代,测量其精度并增加k值直至达到峰值精度。
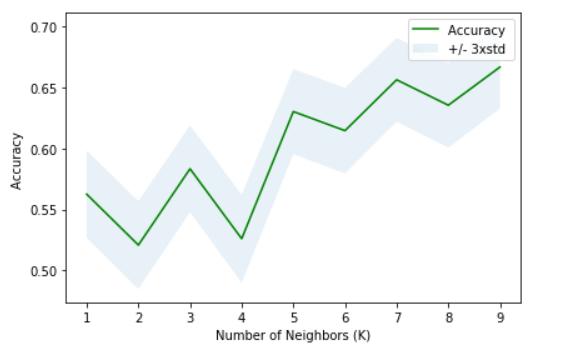
通过将预测模型与训练模型拟合,并使用该预测模型对测试数据集中的数据点进行分类,可以使用此k-max值预测模型进一步分析数据集。
决策树分类器
决策树分类器使用与K最近邻居不同的方法。 首先查看训练模型中的所有数据点并评估一个自变量,然后根据该变量的值为其分配是(1)或否(0)标签。 然后,它基于先前一个或多个自变量的输出进行其他自变量,以得出Y或N的最终标签作为预测结果。
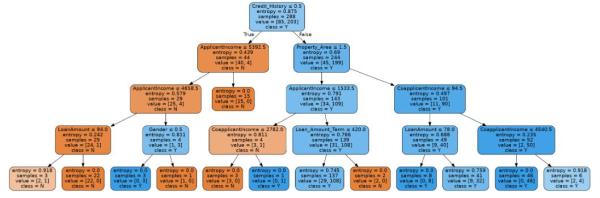
从决策树分类器训练数据集生成的预测模型可用于预测测试数据集中的数据点的类别。
混淆矩阵
混淆矩阵是用于分类的表,用于显示正确预测了多少个值以及错误预测了多少个值。 错误有两种类型:I型错误和II型错误。 I类错误被认为是误报,即归为正的负值。 II型错误是假负数,即被归类为负数的正值。
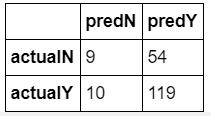
可以使用度量标准(例如精度,召回率和准确性)使用混淆矩阵来计算分类性能。
精确
精度用于查看实际记录的正值中有多少是正值。 其公式为TP /(TP + FP)。 对于上面的混淆矩阵,精度为:119 /(119 + 54)= 0.69
召回
召回率也称为真实阳性率。 它计算真实正值在实际正值中的比例。 其公式为TP /(TP + FN)。 回忆上面的混淆矩阵是119 /(119 + 10)= 0.92
真实负利率
真实负比率衡量真实负数在实际负数中的比例。 其公式为TN /(TN + FP)。 对于上面的混淆矩阵,它是9 /(9 + 54)= 0.15。
准确性
准确度就是所有准确记录的值的总和除以所有记录值的总和。 其公式为(TP + TN)/(TP + TN + FP + FN)。 上面的混淆矩阵的精度为(119 + 9)/(119 + 9 +54 + 10)= 0.67。
F-1分数
F-1分数类似于r平方分数。 它衡量自变量对自变量的解释程度。 通过将预测值与实际值进行比较来完成此操作。 它越接近1,则预测模型越强。 可以针对不同分类方法的预测模型测量F-1分数,以决定使用哪种分类方法。
结论
机器学习是一个能够指导我们在日常活动中做出有效决策的领域。 这将在将来帮助人类和公司做出明智的决策时非常有帮助。 例如,分类可以告诉我们是否要投资某个业务,而回归可以告诉我们如果投资该业务我们可能赚多少钱。
作者:闻数起舞_今日头条
原文链接:http://机器学习的工作原理 > Photo credit: https://upload.wikimedia.org/wikipedia/commons/4/41/Machine_learning.jpg 机器学习是一种数据分析技术,可在数据集上构建预测模型,以提供有用的答案,这些答案可�
转载请注明:www.ainoob.cn » 机器学习的工作原理





