数据科学就是关于数据的。它是任何数据科学或机器学习项目的关键。在大多数情况下,当我们从不同的资源收集数据或从某处下载数据时,几乎有95%的可能性我们的数据中包含缺失的值。我们不能对包含缺失值的数据进行分析或训练机器学习模型。这就是为什么我们90%的时间都花在数据预处理上的主要原因。我们可以使用许多技术来处理丢失的数据。在这个文章中,我将分享处理数据缺失的9种方法,但首先让我们看看为什么会出现数据缺失以及有多少类型的数据缺失。

不同类型的缺失值
缺失的值主要有三种类型。
- 完全随机缺失(MCAR):当数据为MCAR时,如果所有观测的缺失概率都相同,则一个变量完全随机缺失,这意味着数据缺失与数据集中任何其他观察到的或缺失的值完全没有关系。换句话说,那些缺失的数据点是数据集的一个随机子集。
- 丢失数据不是随机的(MNAR):顾名思义,丢失的数据和数据集中的任何其他值之间存在某种关系。
- 随机丢失(MAR):这意味着数据点丢失的倾向与丢失的数据无关,但与数据集中其他观察到的数据有关。
数据集中缺少值的原因有很多。例如,在数据集的身高和年龄,会有更多年龄列中缺失值,因为女孩通常隐藏他们的年龄相同的如果我们准备工资的数据和经验,我们将有更多的薪水中的遗漏值因为大多数男人不喜欢分享他们的薪水。在更大的情况下,比如为人口、疾病、事故死亡者准备数据,纳税人记录通常人们会犹豫是否记下信息,并隐藏真实的数字。即使您从第三方资源下载数据,仍然有可能由于下载时文件损坏而丢失值。无论原因是什么,我们的数据集中丢失了值,我们需要处理它们。让我们看看处理缺失值的9种方法。
这里使用的也是经典的泰坦尼克的数据集
让我们从加载数据集并导入所有库开始。
- import pandas as pd
- df=pd.read_csv("data/titanic.csv",usecols=['Age','Cabin','Survived'])
- df.isnull().mean()
- df.dtypes
运行上述代码块后,您将看到Age、Cabin和装载装载包含空值。Age包含所有整数值,而Cabin包含所有分类值。
1、均值、中值、众数替换
在这种技术中,我们将null值替换为列中所有值的均值/中值或众数。
平均值(mean):所有值的平均值
- def impute_nan(df,column,mean):
- df[column+'_mean']=df[column].fillna(mean) ##NaN -> mean
- impute_nan(df,'Age',df.Age.mean()) ##mean of Age(29.69)
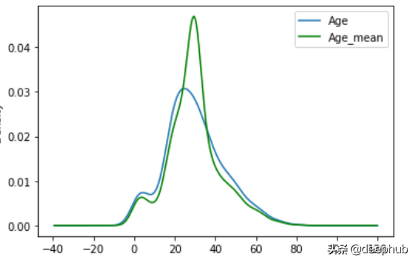
中值(median):所有值的中心值
- def impute_nan(df,column,median):
- df[column+'_mean']=df[column].fillna(median)
- impute_nan(df,'Age',df.Age.median()) ##median of Age(28.0)
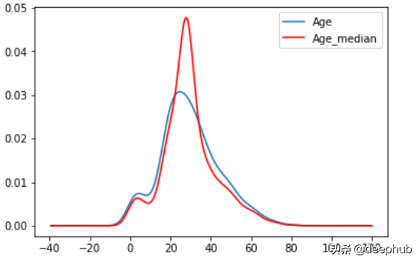
众数(mode):最常见的值
- def impute_nan(df,column,mode):
- df[column+'_mean']=df[column].fillna(mode)
- impute_nan(df,'Age',df.Age.mode()) ##mode of Age(24.0)
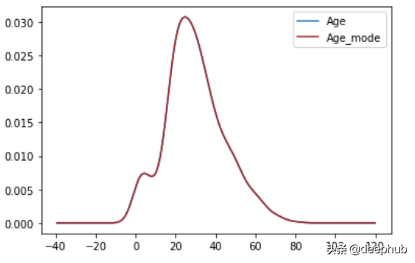
优点
- 易于实现(对异常值健壮)
- 获得完整数据集的更快方法
缺点
- 原始方差的变化或失真
- 影响相关性
- 对于分类变量,我们需要众数。平均值和中位数都不行。
2、随机样本估算
在这种技术中,我们用dataframe中的随机样本替换所有nan值。它被用来输入数值数据。我们使用sample()对数据进行采样。在这里,我们首先取一个数据样本来填充NaN值。然后更改索引,并将其替换为与NaN值相同的索引,最后将所有NaN值替换为一个随机样本。
优点
- 容易实现
- 方差失真更小
缺点
- 我们不能把它应用于每一种情况
用随机样本注入替换年龄列NaN值
- def impute_nan(df,variable):
- df[variable+"_random"]=df[variable]
- ##It will have the random sample to fill the na
- random_sample=df[variable].dropna().sample(df[variable].isnull().sum(),random_state=0)
- ##pandas need to have same index in order to merge the dataset
- random_sample.index=df[df[variable].isnull()].index #replace random_sample index with NaN values index
- #replace where NaN are there
- df.loc[df[variable].isnull(),variable+'_random']=random_sample
- col=variable+"_random"
- df = df.drop(col,axis=1)
- impute_nan(df,"Age")
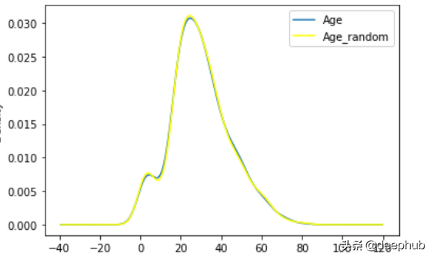
3、用新特性获取NAN值
这种技术在数据不是完全随机丢失的情况下最有效。在这里,我们在数据集中添加一个新列,并将所有NaN值替换为1。
优点
- 容易实现
- 获取了了NaN值的重要性
缺点
- 创建额外的特性(维度诅咒)
- import numpy as np
- df['age_nan']=np.where(df['Age'].isnull(),1,0)
- ## It will create one new column that contains value 1 in the rows where Age value is NaN, otherwise 0.
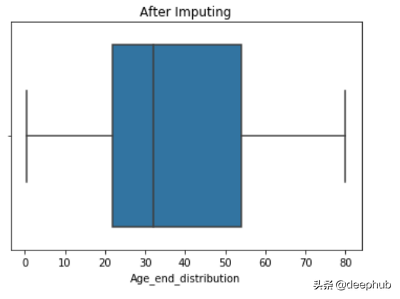
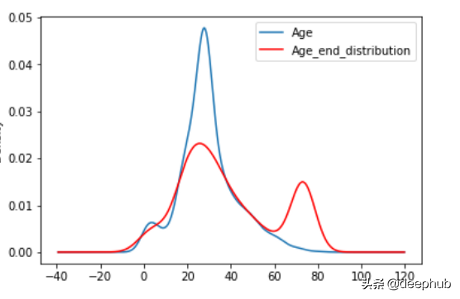
4、End of Distribution
在这种技术中,我们用第3个标准偏差值(3rd standard deviation)替换NaN值。它还用于从数据集中删除所有异常值。首先,我们使用std()计算第3个标准偏差,然后用该值代替NaN。优点
- 容易实现。
- 抓住了缺失值的重要性,如果有的话。
缺点
- 使变量的原始分布失真。
- 如果NAN的数量很大。它将掩盖分布中真正的异常值。
- 如果NAN的数量较小,则替换后的NAN可以被认为是一个离群值,并在后续的特征工程中进行预处理。
- def impute_nan(df,variable,median,extreme):
- df[variable+"_end_distribution"]=df[variable].fillna(extreme)
- extreme=df.Age.mean()+3*df.Age.std() ##73.27--> 3rd std deviation
- impute_nan(df,'Age',df.Age.median(),extreme)

5、任意值替换
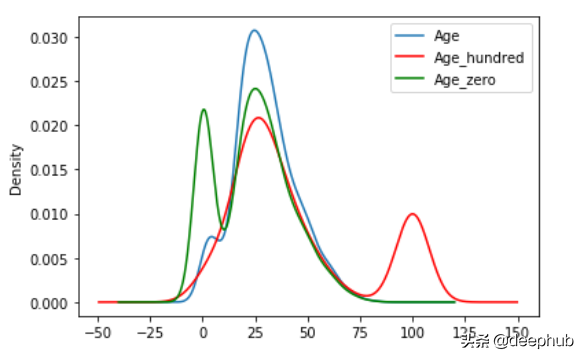
在这种技术中,我们将NaN值替换为任意值。任意值不应该更频繁地出现在数据集中。通常,我们选择最小离群值或最后离群值作为任意值。
优点
- 容易实现
- 获取了缺失值的重要性,如果有的话
缺点
- 必须手动确定值。
- def impute_nan(df,var):
- df[var+'_zero']=df[var].fillna(0) #Filling with 0(least outlier)
- df[var+'_hundred']=df[var].fillna(100) #Filling with 100(last)
- impute_nan(df,'Age')
6、频繁类别归责
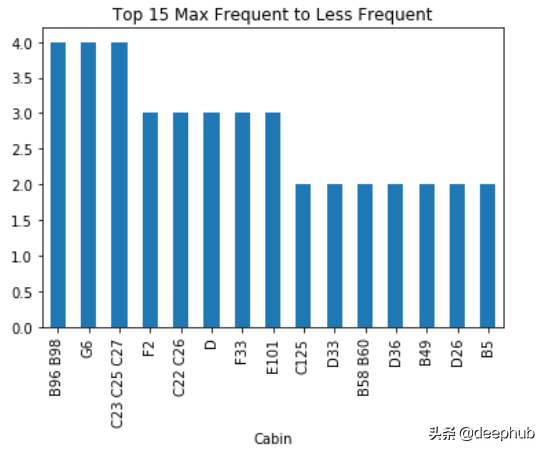
该技术用于填充分类数据中的缺失值。在这里,我们用最常见的标签替换NaN值。首先,我们找到最常见的标签,然后用它替换NaN。
优点
- 容易实现
缺点
- 由于我们使用的是更频繁的标签,所以如果有很多NaN值,它可能会以一种过度表示的方式使用它们。
- 它扭曲了最常见的标签之间的关系。
- def impute_nan(df,variable):
- most_frequent_category=df[variable].mode()[0] ##Most Frequent
- df[variable].fillna(most_frequent_category,inplace=True)
- for feature in ['Cabin']: ##List of Categorical Features
- impute_nan(df,feature)
7、nan值视为一个新的分类
在这种技术中,我们只需用一个新的类别(如Missing)替换所有NaN值。
- df['Cabin']=df['Cabin'].fillna('Missing') ##NaN -> Missing
8、使用KNN填充
在这项技术中,我们使用sklearn创建一个KNN imputer模型,然后我们将该模型与我们的数据进行拟合,并预测NaN值。它被用来计算数值。这是一个5步的过程。
- 创建列列表(整数、浮点)
- 输入估算值,确定邻居。
- 根据数据拟合估算。
- 转换的数据
- 使用转换后的数据创建一个新的数据框架。
优点
- 容易实现
- 结果一般情况下会最好
缺点
- 只适用于数值数据
我们在上篇文章中已经有过详细的介绍,这里就不细说了
在python中使用KNN算法处理缺失的数据
9、删除所有NaN值
它是最容易使用和实现的技术之一。只有当NaN值小于10%时,我们才应该使用这种技术。
优点:
- 容易实现
- 快速处理
缺点:
- 造成大量的数据丢失
- df.dropna(inplace=True) ##Drop all the rows that contains NaN
总结
还有更多处理丢失值的其他技术。我们的目标是找到最适合我们的问题的技术,然后实施它。处理丢失的值总是一个更好的主意,但有时我们不得不删除所有的值。它基本上取决于数据的类型和数量。
最有,所有的代码在这里都能找到:https://github.com/Abhayparashar31/feature-engineering
AIX人工智能社区

作者:deephub_今日头条
原文链接:https://www.toutiao.com/a6889612835328885252/
转载请注明:www.ainoob.cn » 机器学习中处理缺失值的9种方法






