即将开播:5月14日,Jenkins在K8S下的三种部署流程和实战演示
【51CTO.com快译】如今,机器学习(Machine Learning,ML)和人工智能(Artificial Intelligence,AI)的相关算法越来越深度地融合到了我们的社会与生活中,并且在金融科技、医疗保健、以及交通运输等各个方面起到了关键性的驱动与促进作用。如果说20世纪下半叶,人类得益于以互联网为基础架构的计算力和连通性总体进步的话,那么人类在21世纪正在逐步走向由智能计算和智能机器的迭代。其中,以深度学习(Deep Learning,DL)为首的此类新型的计算范式通常属于“监督学习(supervised learning)”的范畴。其对应的应用–深度神经网络(Deep Neural Networks,DNN),在疾病分类、图像分割、以及语音识别等高科技系统和应用方面,都取得了令人兴奋进步和惊人的成功。
不过,深度神经网络系统往往需要大量的训练数据,以及已知答案的带标签样本,才能正常地工作。并且,它们目前尚无法完全模仿人类学习和运用智慧的方式。几乎所有的AI专家都认为:仅仅增加基于深度神经网络系统的规模和速度,是永远不会产生真正的“类人(human-like)”AI系统的。
因此,人们开始转向那些“监督学习”以外的ML和AI计算范式和算法,试图顺应人类的学习过程曲线。该领域研究的最广泛的当属–强化学习(Reinforcement Learning,RL)。在本文中,我们通过相关知识和算法的介绍,和您简要地讨论了如何将深度学习和强化学习融合在一起,产生所谓深度强化学习(Deep Reinforcement Learning,DRL),这一强大的AI系统。
什么是深度强化学习?
众所周知,人类擅长解决各种挑战性的问题,从低级的运动控制(如:步行、跑步、打网球)到高级的认知任务(如:做数学题、写诗、交谈)。而强化学习则旨在使用软、硬件之类的代理(具体含义请见下文),通过明确的定义、合理的设计等相关算法,来模仿人类的此类行为。也就是说,这种学习范式的目标不是以简单的输入/输出方式(如:独立的深度学习系统),来映射带有标签的示例,而是要建立一种策略,通过帮助智能化的代理,以某种顺序进行动作(具体含义请见下文),从而实现某项最终目标。
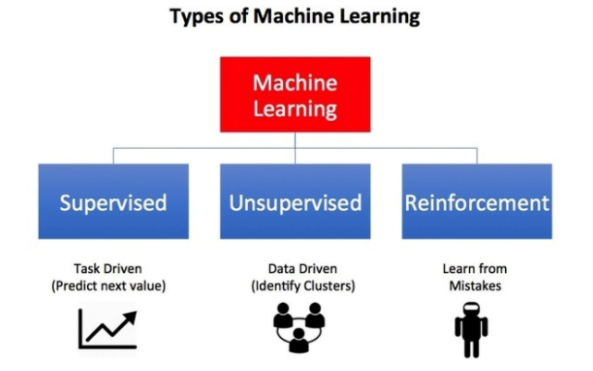
图片来源:《机器学习有哪些类型》(请参见– https://towardsdatascience.com/what-are-the-types-of-machine-learning-e2b9e5d1756f)
其实,强化学习是一些面向目标(goal-oriented)的算法,它们能够学习如何实现复杂的目标,或通过多个步骤沿着某个特定维度来实现目标的最大化。下面是强化学习在实际应用中的三种示例:
- 让一个棋盘游戏的获胜率最大化。
- 让财务模拟某笔交易的最大收益。
- 在复杂的环境中,保障机器人在移动过程中的错误行径最小。
如下图所示,其基本想法是:代理通过传感器接收来自所处环境中的输入数据,使用强化学习的算法对其进行处理,然后采取相应的行动以达到预定的目标。可见,这与人类在日常生活中的行为非常相似。
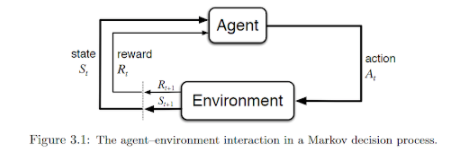
资料来源:《强化学习的简介》(请参见–http://incompleteideas.net/book/bookdraft2017nov5.pdf)
深度强化学习中的基本定义
我们在开展后续讨论之前,了解强化学习中所涉及和使用到的各种关键术语是非常实用的。其中包括:
- 代理(Agent):一种软、硬件机制。它通过与周围环境的交互,来采取相应的措施。例如:一架正在送货的无人机,或是视频游戏中引导超级玛丽前进的程序。当然,算法本身也属于代理。
- 动作(Action):代理可以采取的各种可能性动作。虽然动作本身具有一定的不言自明性(self-explanatory),但是我们仍需要让代理能够从一系列离散的、且可能的动作中予以选择。
- 环境(Environment):外界环境与代理之间存在着相互作用,以及做出响应的关系。环境将代理当前的状态和动作作为输入,并将代理的奖励(具体含义请见下文)和下一个状态作为输出。
- 状态(State):状态是代理自行发现的、具体且直接的情况,包括:特定的地点、时刻、以及将代理与其他重要事物相关联的瞬时配置。例如:一个棋盘在某个特定时刻的棋子布局。
- 奖励(Reward):奖励是一种反馈,我们可以据此衡量代理在给定状态下各种动作的成败。例如:在下棋游戏中,吃掉对手的象这一重要的动作会得到某种奖励,而赢得整个游戏则会获得更大的奖励。负奖励(Negative rewards)有着相反的含义,例如:下输了一盘棋。
- 折扣因子(Discount factor):折扣因子是一个乘数。由代理发现的未来奖励乘以该因子,以减弱此类奖励针对代理当前动作选择的累积影响。这是强化学习的核心,也就是通过逐渐降低未来奖励的值,以便对最近的动作给予更多的权值。这对于基于“延迟动作(delayed action)”原理的范式而言,是至关重要的。
- 策略(Policy):它是代理用来根据当前状态确定下一步动作的策略。它能够将不同的状态映射到各种动作上,以承诺最高的奖励。
- 值(Value):它被定义为在特定的策略下,当前状态带有折扣的长期预期奖励(并非短期奖励)。
- Q值(Q-value)或动作值(action-value):与“值”的不同之处在于,Q值需要一个额外的参数,也就是当前的动作。它是指一个动作在特定的策略下,由当前状态产生的长期奖励。
常见的数学(算法)框架
在解决强化学习的相关问题时,我们经常会用到如下的数学框架:
马尔可夫决策过程(Markov Decision Process,MDP):几乎所有的强化学习问题都可以被构造为MDP。MDP中的所有状态都具有“马尔可夫”属性,即:未来仅取决于当前状态,而非状态的历史,这一事实。
Bellman方程(Bellman Equations):它是一组将值函数分解为即时奖励加上折扣未来值的方程。
动态编程(Dynamic Programming,DP):如果当系统模型(代理+环境)完全已知时,根据Bellman方程,我们就可以使用动态编程,来迭代评估值函数,并改进相应的策略。

值迭代(Value iteration):这是一种算法,它通过迭代式地改进对于值的估计,以计算出具有最佳状态值的函数。该算法先将值函数初始化为任意随机值,然后重复更新Q值和值函数的各个值,直到它们收敛为止。

策略迭代(Policy iteration):由于代理仅关注寻找最优的策略,而最优策略有时会在价值函数之前就已经收敛了。因此,策略迭代不应该重复地改进值函数的估算,而需要在每一步上重新定义策略,并根据新的策略去计算出值来,直到策略收敛为止。
Q学习(Q-learning):作为一种无模型(model-free)学习算法的示例,它并不会假定代理对于状态的转换和奖励模型已经了如指掌,而是“认为”代理将通过反复的试验,来发现正确的动作。因此,Q学习的基本思想是:在代理与环境交互过程中,通过观察Q值函数的样本,以接近“状态-动作对(state-action pairs)”的Q函数。这种方法也被称为时分学习(Time-Difference Learning)。

上图是一个通过Q学习(即:尝试和错误观察),来解决强化学习问题的示例(请参见– https://gym.openai.com/envs/MountainCar-v0)。在示例所处环境中,动力学和模型,即运动的整体物理原理,都是未知的。
Q学习所存在的问题
Q学习是解决强化学习相关问题的一种简单而强大的方法。从理论上讲,我们可以在不引入其他数学复杂性的情况下,将其延伸到各种大而复杂的问题上。其实,Q学习可以借助递归方程来完成,其中:
Q(s,a):Q值函数
s:状态
s’,s”:未来状态
a:动作
γ:折现率
对于小的问题,我们可以从对所有的Q值(Q-values)做出任意假设开始,通过反复的试验,Q表(Q-table)不断得以更新,进而让政策逐渐趋于一致。由于更新和选择动作是随机执行的,因此最优的策略可能并不代表全局最优,但它可以被用于所有实际的目的。
不过,随着问题规模的增加,针对某个大问题所构造并存储一组Q表,将很快成为一个计算性的难题。例如:在象棋或围棋之类的游戏中,可能的状态数(即移动的顺序)与玩家需要提前计算的步数,成指数式的增长。因此:
- 保存和更新该表所需的内存量,将随着状态数的增加而增多。
- 探索每个状态,进而创建Q表所需的时间,将变得无法预知。
针对上述问题,我们需要用到诸如深度Q学习(Deep-Q learning)之类的技术,并使用机器学习来试着解决。
深度Q学习
顾名思义,深度Q学习不再维护一张大型的Q值表,而是利用神经网络从给定的动作和状态输入中去接近Q值函数。在一些公式中,作为输入的状态已经被给出,而所有可能的动作Q值都作为输出被产生。此处的神经网络被称为Deep-Q–Network(DQN),其基本思想如下图所示:
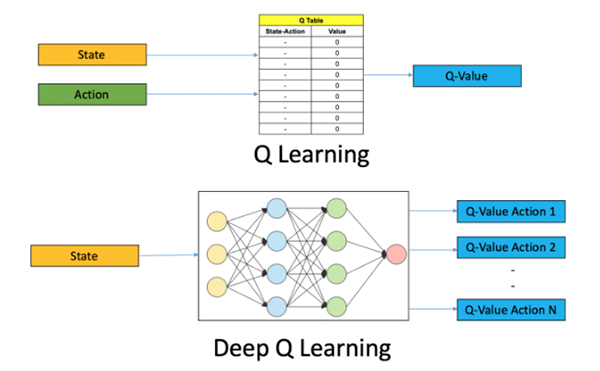
图片来源:在Python中使用OpenAI Gym进行深度Q学习的入门(请参见–https://www.analyticsvidhya.com/blog/2019/04/introduction-deep-q-learning-python/)
不过DQN在使用的时候有一定的难度。而在传统的深度学习算法中,由于我们对输入样本进行了随机化处理,因此输入的类别在各种训练批次之间,都是非常均衡且稳定的。在强化学习中,搜索会在探索阶段(exploration phase)不断被改进,进而不断地更改输入和动作的空间。此外,随着系统逐渐加深对于环境的了解,Q的目标值也会自动被更新。简而言之,对于简单的DQN系统而言,输入和输出都是经常变化的。
为了解决该问题,DQN引入了体验重播(experience replay)和目标网络(target network)的概念来减缓变化,进而以受控且稳定的方式逐步学习Q表。
其中,体验重播在特定的缓冲区中存储一定量的状态动作奖励值(例如,最后有一百万个)。而对于Q函数的训练,它使用来自缓冲区的随机样本的小批量来完成。因此,训练样本不但是随机的,并且能够表现得更接近传统深度学习中监督学习的典型情况。这有点类似于系统具有高效的短期记忆,我们在探索未知环境时可以用到它。
此外,DQN通常使用两个网络来存储Q值。一个网络不断被更新,而另一个网络(即:目标网络)与第一个网络以固定的间隔进行同步。我们使用目标网络来检索Q值,以保证目标值的变化波动较小。
深度强化学习的实际应用
进行Atari游戏
成立于2010年的DeepMind(请参见–https://deepmind.com/)是一家位于伦敦的初创公司。该公司于2014年被Google的母公司Alphabet所收购,并成功地将卷积神经网络(CNN)和Q学习结合起来用于训练。它为深度强化学习领域做出了开拓性贡献。例如:某个代理可以通过原始像素的输入(如某些感知信号),来进行Atari游戏。欲知详情,请参见–https://deepmind.com/research/publications/playing-atari-deep-reinforcement-learning)

图片来源:DeepMind在arXiV上有关Atari的文章(2013年)(请参见–https://arxiv.org/pdf/1312.5602v1.pdf)。
Alpha Go和Alpha Go Zero
3000多年前起源于中国的围棋,凭借着其复杂性,被称为AI最具挑战性的经典游戏。标准的AI处理方法是:使用搜索树(search tree)来测试所有可能的移动和位置。但是,AI无法处理大量棋子的可能性移动,或评估每个可能性棋盘位置的强度。
借助深度强化学习的技术和新颖的搜索算法,DeepMind开发了AlphaGo,这是第一个击败了人类职业围棋选手的计算机程序,第一个击败了围棋世界冠军的程序,也可以说是历史上最强的围棋选手。

图片来源:https://medium.com/point-nine-news/what-does-alphago-vs-8dadec65aaf
Alpha Go的升级版本被称为Alpha Go Zero。该系统源于一个对围棋规则一无所知的神经网络。该神经网络通过与功能强大的搜索算法相结合,不断和自己下棋,与自己进行对抗。在重复进行游戏的过程中,神经网络会通过持续调整和更新,来预测下棋的步骤,并最终成为游戏的赢家。通过不断的迭代,升级后的神经网络与搜索算法重新组合,以提升系统的性能,并不断提高与自己对弈的水平。
图片来源:从零开始的Alpha Go Zero(请参见–https://deepmind.com/blog/article/alphago-zero-starting-scratch)
在石油和天然气行业中的应用
荷兰皇家壳牌公司一直在其勘探和钻探工作中通过强化学习的部署,以降低高昂的天然气开采成本,并改善整个供应链中的多个环节。那些经过了历史钻探数据训练的深度学习算法,以及基于物理学的高级模拟技术,让天然气钻头在穿过地表后,能够智能地移动。深度强化学习技术还能够实时地利用来自钻头的机械数据(如:压力和钻头的温度),以及地表下的地震勘测数据。欲知详情,请参见–https://www.forbes.com/sites/bernardmarr/2019/01/18/the-incredible-ways-shell-uses-artificial-intelligence-to-help-transform-the-oil-and-gas-giant/#187951c42701。
自动驾驶
虽然不是主流应用,但是深度强化学习在自动驾驶汽车的各种挑战性问题上,也发挥着巨大的潜力。其中包括:
- 车辆控制
- 坡道合并
- 个人驾驶风格的感知
- 针对安全超车的多目标强化学习
欲知详情,请参见– https://arxiv.org/pdf/1901.01536.pdf。
总结
深度增强学习是真正可扩展的通用人工智能(Artificial general intelligence,AGI),是AI系统的最终发展方向。在实际应用中,它催生了诸如Alpha Go之类的智能代理,实现了自行从零开始学习游戏规则(也就是人们常说的:外部世界的法则),而无需进行明确的训练和基于规则的编程。我们乐观地认为,深度增强学习的未来和前景将是一片光明。
原标题:What You Need to Know About Deep Reinforcement Learning,作者: Kevin Vu
【51CTO译稿,合作站点转载请注明原文译者和出处为51CTO.com】
作者:陈峻译_51CTO
原文链接:http://ai.51cto.com/art/202005/616310.htm
转载请注明:www.ainoob.cn » 你该知道的深度强化学习相关知识





