本文经AI新媒体量子位(公众号ID:QbitAI)授权转载,转载请联系出处。
江山代有才人出,开源一波更比一波强。
就在最近,一个简洁、轻巧、快速的深度强化学习平台,完全基于Pytorch,在Github上开源。
如果你也是强化学习方面的同仁,走过路过不要错过。
而且作者,还是一枚清华大学的本科生——翁家翌,他独立开发了”天授(Tianshou)“平台。
没错,名字就叫“天授”。

Why 天授?
主要有四大优点:
1、速度快,整个平台只用1500行左右代码实现,在已有的toy scenarios上面完胜所有其他平台,比如3秒训练一个倒立摆(CartPole)。
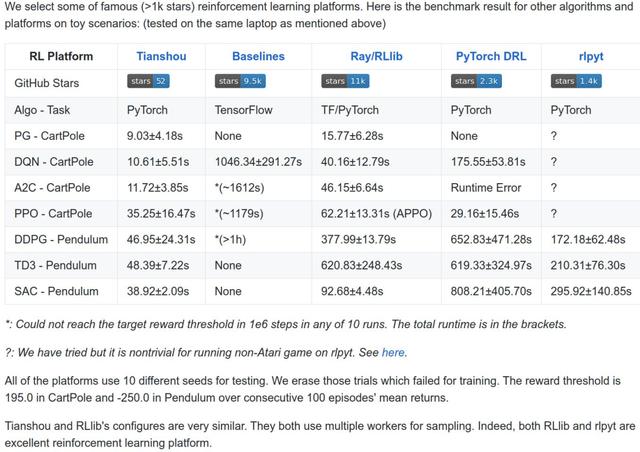
2、模块化,把所有policy都拆成4个模块:
init:策略初始化。process_fn:处理函数,从回放缓存中处理数据。call:根据观测值计算操作learn:从给定数据包中学习
只要完善了这些给定的接口就能在100行之内完整实现一个强化学习算法。
3、天授平台目前支持的算法有:
Policy Gradient (PG)
Deep Q-Network (DQN)
Double DQN (DDQN) with n-step returns
Advantage Actor-Critic (A2C)
Deep Deterministic Policy Gradient (DDPG)
Proximal Policy Optimization (PPO)
Twin Delayed DDPG (TD3)
Soft Actor-Critic (SAC)
随着项目的开发,会有更多的强化学习算法加入天授。
4、接口灵活:用户可以定制各种各样的训练方法,只用少量代码就能实现。
如何使用天授
以DQN(Deep-Q-Network)算法为例,我们在天授平台上使用CartPole小游戏,对它的agent进行训练。
配置环境
习惯上使用OpenAI Gym,如果使用Python代码,只需要简单的调用Tianshou即可。
CartPole-v0是一个可应用DQN算法的简单环境,它拥有离散操作空间。配置环境时,你需要注意它的操作空间是连续还是离散的,以此选择适用的算法。
设置多环境层
你可以使用现成的gym.Env:

也可以选择天授提供的三种向量环境层:VectorEnv、SubprocVectorEnv和RayVectorEnv,如下所示:

示例中分别设置了8层和100层环境。
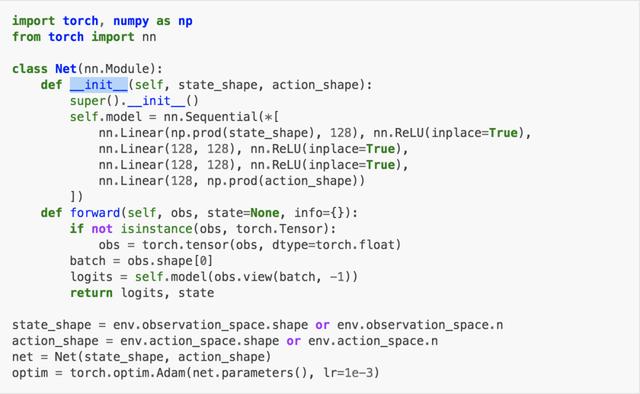
建立网络
天授支持任意用户自主定义的网络或优化器,但有接口限制。

以下是一个正确的示例:
设置策略
我们使用已定义的net和optim(有额外的策略超参数)来定义一个策略。下方我们用一个目标网络来定义DQN算法策略。

设置收集器
收集器是天授的关键概念,它使得策略能够高效的与不同环境交互。每一步,收集器都会将该策略的操作数据记录在一个回放缓存中。

训练
天授提供了训练函数onpolicy_trainer和offpolicy_trainer。当策略达到终止条件时,他们会自动停止训练。由于DQN是无策略算法,我们使用offpolicy_trainer。
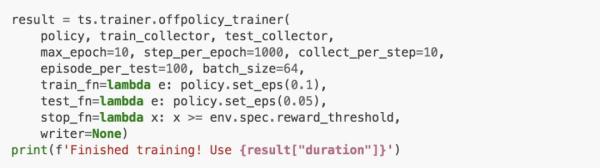
训练器支持TensorBoard记录,方法如下:

将参数writer输入训练器中,训练结果会被记录在TensorBoard中。

记录显示,我们在几乎4秒的时间内完成了对DQN的训练。
保存/加载策略
因为我们的策略沿袭自torch.nn.Module,所以保存/加载策略方法与torch模块相同。

观察模型表现
收集器支持呈现功能,以35帧率观察模型方法如下:

用你自己的代码训练策略
如果你不想用天授提供的训练器也没问题,以下是使用自定义训练器的方法。

上手体验
天授需要Python3环境。以CartPole训练DQN模型为例,输入test_dqn.py代码进行训练,其结果统计如下:

可以看出整个训练过程用时7.36秒,与开发者给出的训练时间符合。
模型训练结果如下:

作者介绍
天授的开发者:翁家翌,清华大学的在读大四本科生。
高中毕业于福州一中,前NOI选手。
大二时作就作为团队主要贡献者获得了强化学习国际比赛vizdoom的冠军。他希望能将天授平台深入开发,成为强化学习平台的标杆。开源也是希望有更多的小伙伴加入这个项目。
传送门:
PyPI提供天授平台下载,你也可以在Github上找到天授的最新版本和其他资料。
PYPI:
https://pypi.org/project/tianshou/
Github天授主页:
https://github.com/thu-ml/tianshou
作者:贾浩楠_量子位
原文链接:https://www.toutiao.com/i6810594752786858499/






