即将开播:4月29日,民生银行郭庆谈商业银行金融科技赋能的探索与实践

你想做计算机视觉吗?
如今,深度学习是必经之路。大规模数据集以及深层卷积神经网络(CNN)的表征能力可提供超准确和强大的模型。但目前仍然只有一个挑战:如何设计模型?
像计算机视觉这样广泛而复杂的领域,解决方案并不总是清晰明了的。计算机视觉中的许多标准任务都需要特别考虑:分类、检测、分割、姿态估计、增强和恢复以及动作识别。尽管最先进的网络呈现出共同的模式,但它们都需要自己独特的设计。
那么,我们如何为所有这些不同的任务建立模型呢?
作者在这里向你展示如何通过深度学习完成计算机视觉中的所有工作!

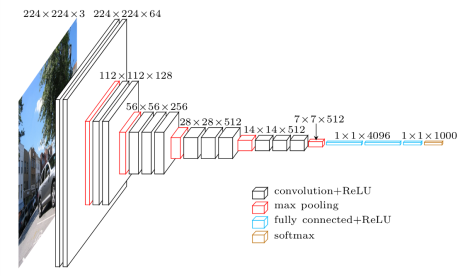
分类
计算机视觉中最出名的就是分类。图像分类网络从一个固定大小的输入开始。输入图像可以有任意数量的通道,但对于RGB图像通常为3。在设计网络时,分辨率在技术上可以是任意大小,只要足够大到能够支持在整个网络中将要进行的向下采样量即可。例如,如果你对网络内的4个像素进行向下采样,则你的输入大小至少应为4²= 16 x 16像素。
随着深入网络,当我们尝试压缩所有信息并降至一维矢量表示形式时,空间分辨率将降低。为了确保网络始终有能力将其提取的所有信息进行处理,我们根据深度的比例增加特征图的数量,来适应空间分辨率的降低。也就是说,我们在向下采样过程中损失了空间信息,为了适应这种损失,我们扩展了特征图来增加我们的语义信息。
在选择了一定数量的向下采样后,特征图被矢量化并输入到一系列完全连接的图层中。最后一层的输出与数据集中的类一样多。

目标检测
目标检测器分为两种:一级和二级。他们两个都以锚框开始。这些是默认的边界框。我们的检测器将预测这些框与地面真相之间的差异,而不是直接预测这些框。
在二级检测器中,我们自然有两个网络:框提议网络和分类网络。框提议网络在认为很有可能存在物体的情况下为边界框提供坐标。再次,这些是相对于锚框。然后,分类网络获取每个边界框中的潜在对象进行分类。
在一级检测器中,提议和分类器网络融合为一个单一阶段。网络直接预测边界框坐标和该框内的类。由于两个阶段融合在一起,所以一级检测器往往比二级检测器更快。但是由于两个任务的分离,二级检测器具有更高的精度。
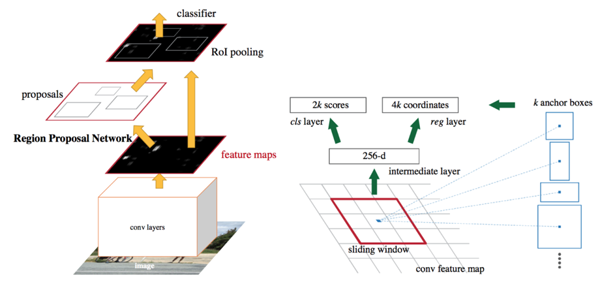
快速RCNN二级目标检测架构
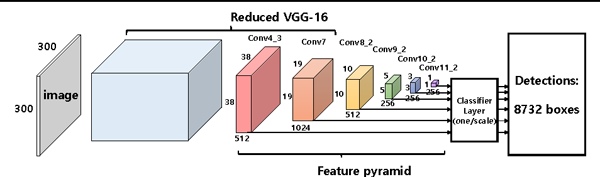
SSD一级目标检测架构

分割
分割是计算机视觉中较独特的任务之一,因为网络既需要学习低级信息,也需要学习高级信息。低级信息可按像素精确分割图像中的每个区域和对象,而高级信息可直接对这些像素进行分类。这导致网络被设计为将来自较早层和高分辨率(低层空间信息)的信息与较深层和低分辨率(高层语义信息)相结合。
如下所示,我们首先通过标准分类网络运行图像。然后,我们从网络的每个阶段提取特征,从而使用从低到高的范围内的信息。每个信息级别在依次组合之前都是独立处理的。当这些信息组合在一起时,我们对特征图进行向上采样,最终得到完整的图像分辨率。
要了解更多关于如何分割与深度学习工作的细节,请查看这篇文章:
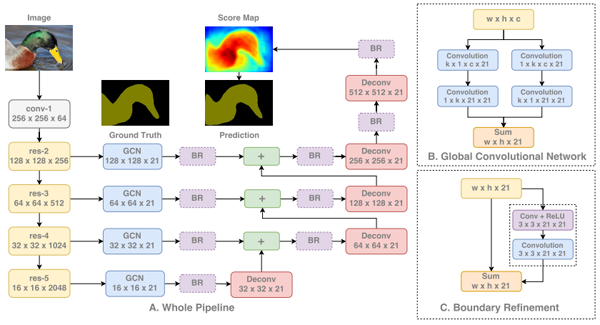
GCN细分架构

姿态估计
姿态估计模型需要完成两个任务:(1)检测图像中每个身体部位的关键点;(2)找出如何正确连接这些关键点。这分以下三个阶段完成:
- 使用标准分类网络从图像中提取特征。
- 给定这些特征,就可以训练一个子网络来预测一组2D热图。每个热图都与一个特定的关键点相关联,并包含每个图像像素关于是否可能存在关键点的置信值。
- 再次给出分类网络的特征,我们训练一个子网络来预测一组2D向量场,其中每个向量场都与关键点之间的关联度进行编码。然后,具有较高关联性的关键点被称为已连接。
用这种方法训练子网络的模型,可以联合优化关键点的检测并将它们连接在一起。
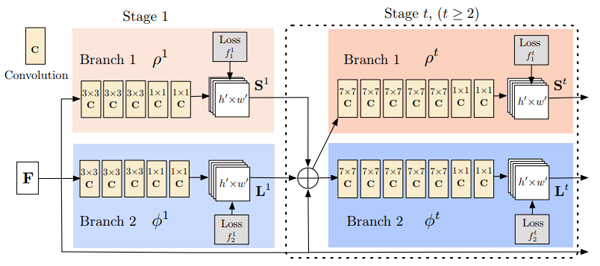
OpenPose姿态估计架构

增强和恢复
增强和恢复网络是它们自己独特的野兽。我们不会对此进行任何向下采样,因为我们真正关心的是高像素/空间精度。向下采样会真正抹杀这些信息,因为它将减少我们为空间精度而拥有的像素数。相反,所有处理都是在全图像分辨率下完成的。
我们开始以全分辨率将想要增强/恢复的图像传递到我们的网络,而无需进行任何修改。网络仅由许多卷积和激活函数组成。这些块通常是受启发的,并且有时直接复制那些最初为图像分类而开发的块,例如残差块、密集块、挤压激励块等。最后一层没有激活函数,即使是sigmoid或softmax也没有,因为我们想直接预测图像像素,不需要任何概率或分数。
这就是所有这些类型的网络。在图像的全分辨率上进行了大量的处理,来达到较高的空间精度,使用了与其他任务相同的卷积。
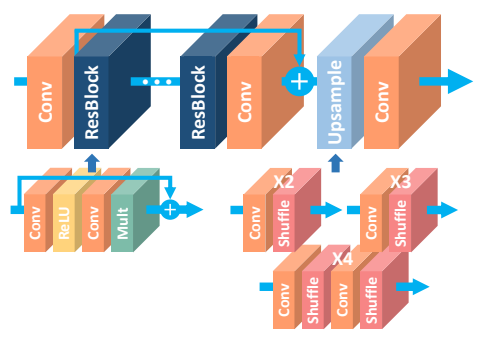
EDSR超分辨率架构

动作识别
动作识别是少数几个需要视频数据才能正常运行的应用程序之一。要对一个动作进行分类,我们需要了解随着时间推移,场景中发生的变化, 这自然导致我们需要视频。我们的网络必须经过训练来学习时空信息,即时空变化。最完美的网络是3D-CNN。
顾名思义,3D-CNN是使用3D卷积的卷积网络。它们与常规CNN的不同之处在于,卷积是在3维上应用的:宽度、高度和时间。因此,每个输出像素都是根据其周围像素以及相同位置的前一帧和后一帧中的像素进行计算来预测的。

直接大量传递图像
视频帧可以通过几种方式传递:
- 直接在大批量中,例如第一个图。由于我们正在传递一系列帧,因此空间和时间信息都是可用的。
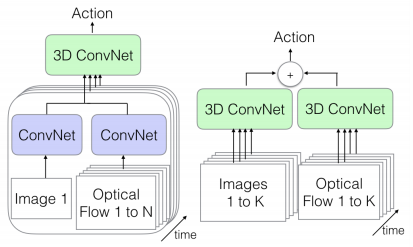
单帧+光流(左) 视频+光流(右)
- 我们还可以在一个流中传递单个图像帧(数据的空间信息),并从视频中传递其相应的光流表示形式(数据的时间信息)。我们将使用常规2D CNN从这两者中提取特征,然后再将其组合起来传递给我们的3D CNN,后者将两种类型的信息进行合并。
2. 将帧序列传递给一个3D CNN,并将视频的光流表示传递给另一个3D CNN。这两个数据流都具有可用的空间和时间信息。鉴于我们正在对视频的两种不同表示(均包含我们的所有信息)进行特定处理,因此这是最慢的选择,但也可能是最准确的选择。
所有这些网络都输出视频的动作分类。
作者:George Seif_AI科技大本营
原文链接:https://mp.weixin.qq.com/s/1xRVTd5u9TiP56eDnO2iRQ
转载请注明:www.ainoob.cn » 如何通过深度学习,完成计算机视觉中的所有工作?






