微分方程与机器学习作为 AI 领域建模的两种方法,各自有什么优势?
微分方程(DE)与机器学习(ML)类数据驱动方法都足以驱动 AI 领域的发展。二者有何异同呢?本文进行了对比。
微分方程模型示例
纳维-斯托克斯方程(气象学)
这一模型被用于天气预测。它是一个混沌模型,当输入存在一点点不准确,预测结果就会大相径庭。这就是为什么天气预报经常是错误的,天气模拟使用超级计算机完成。
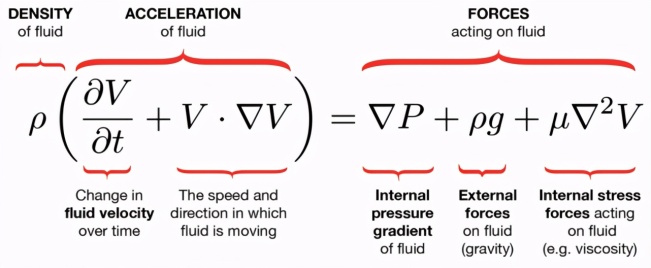
爱因斯坦场方程(物理学)
爱因斯坦场方程描述了重力定律,也是爱因斯坦广义相对论的数学基础。
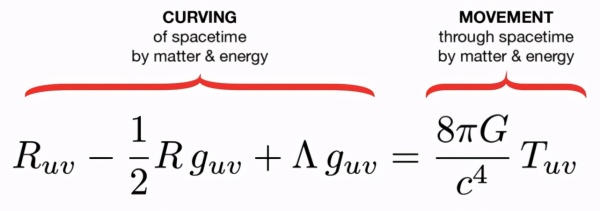
Black-Scholes(金融)
Black-Scholes 模型在股票市场为金融衍生品定价。
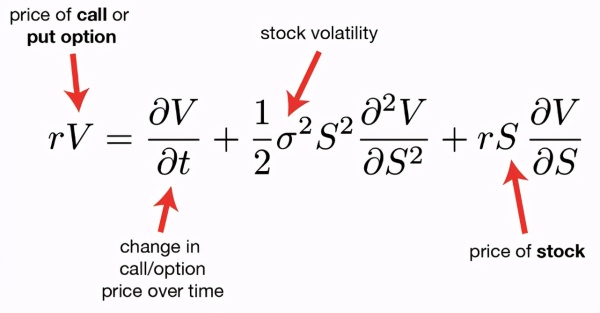
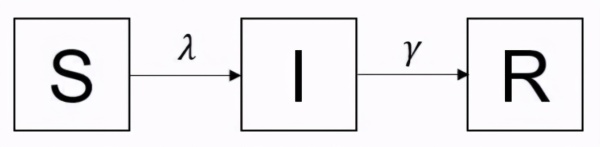
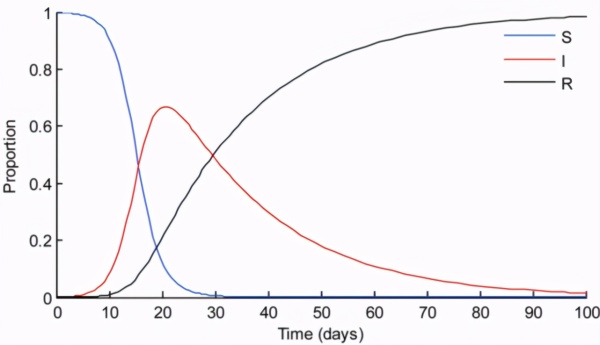
SIR 模型(流行病学)
SIR 是基础的房室模型,可以描述传染病的传播情况。

为什么以上 4 个方程都是微分方程?因为它们都包含某些未知函数的导数(即变化率)。这些未知函数(如 SIR 模型中的 S(t)、I(t) 和 R(t))被称为微分方程的解。
我们再来看一个模型。
Murray-Gottman(心理学)
这个模型用来预测浪漫关系的期限。根据心理学家 John Gottman 的开创性研究成果,持续的乐观氛围是预测婚姻成功的重要指标。
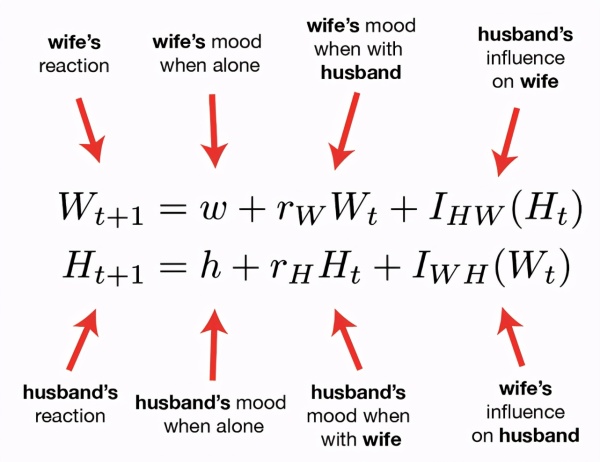
请注意 Murray-Gottman「爱情模型」实际上是一个差分方程(微分方程的一种姊妹模型)。差分方程输出离散的数字序列(例如,每 5 年的人口普查结果),而微分方程则建模连续数值(即持续发生的事件)。
上述 5 个模型(微分和差分方程)都是机械模型,我们可以在其中自行选择系统的逻辑、规则、结构或机制。当然,并不是每次试验都会成功,反复试验在数学建模中非常重要。
纳维 – 斯托克斯方程假定大气是流动的流体,上述方程式就是来自流体动力学。广义相对论假设在一种特殊的几何形态下,时空会发生扭曲。爱因斯坦提出关于时空扭曲的一些重要想法,数学家 Emmy Noether 和 David Hilbert 将这些想法整合到爱因斯坦场方程中。SIR 模型假设病毒是通过感染者与未感染者之间的直接接触传播的,并且感染者会以固定的速率自动恢复。
使用机械模型时,观察和直觉会指导模型的设计,而数据则用于后续验证假设。
所有这些都与经验模型或数据驱动模型形成鲜明对比,经验或数据驱动模型首先从数据出发。这其中就包括机器学习模型,其算法通过输入足够的高质量样本来学习系统的基础逻辑或规则。当人类很难分析或定义系统的机制时,这样的方法是很明智的。
数学模型的分类
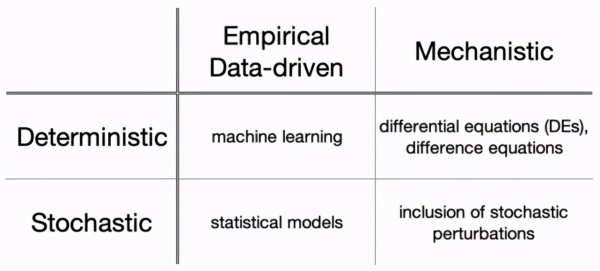
机械模型对驱动系统的底层机制进行了假设,在物理学中很常用。实际上,数学建模是从 17 世纪人们试图解开行星运动规律时才开始发展的。
经验或数据驱动型建模,特别是机器学习,能够让数据来学习系统的结构,这个过程就叫做「拟合」。机器学习对于人类不确定如何将信号从噪声中分离出来的复杂系统格外有效,只需要训练一种聪明的算法,让它来代替你做繁琐的事情。
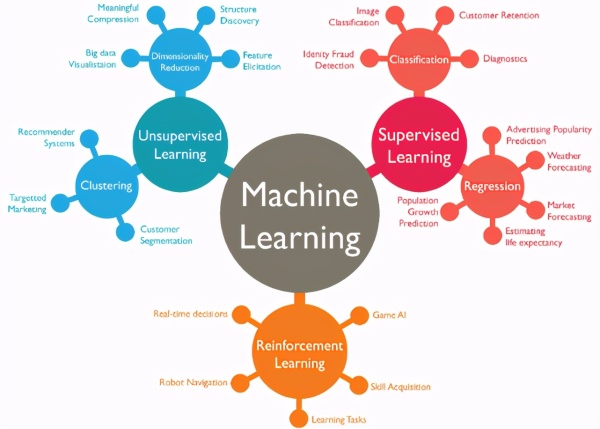
机器学习任务广义上可以分为:
监督学习(即回归与分类)
无监督学习(即聚类和降维)
强化学习
如今机器学习和人工智能系统在日常生活中随处可见。从亚马逊、苹果和谷歌的语音助手到 Instagram、Netflix 和 Spotify 的推荐引擎,再到 Facebook 和 Sony 的人脸识别技术,甚至特斯拉的自动驾驶技术,所有这些都是由嵌入在大量代码下的数学与统计模型驱动的。
我们可以进一步将机械模型和经验模型分为确定性模型(预测是固定的)和随机性模型(预测包含随机性)。
确定性模型忽略随机变化,在相同的初始条件下,总会预测出相同的结果。
随机模型则考虑了随机变化,如系统中单个主体的异质性,比如人、动物、细胞之间就存在细微的差别。
随机性通常会在模型中引入一些现实性,但同时也存在一定的代价。在数学建模中,我们需要考虑模型的复杂性:简单的模型易于分析,但可能缺乏预测能力;复杂的模型具有现实性,但尝试弄清楚模型背后的原理也很重要。因此,我们需要在简单性和可分析性之间进行权衡,正如统计学家 George Box 所说:
所有的模型都是错误的,但其中一些是有用的。
在机器学习和统计学中,模型复杂度被称为「偏差 – 方差权衡」。高偏差模型过于简单,导致欠拟合,高方差模型存储的是噪声而不是信号(即系统的实际结构),会导致过拟合。
微分方程与机器学习示例对比
logistic 微分方程
该方程涉及农业、生物学、经济学、生态学、流行病学等领域。

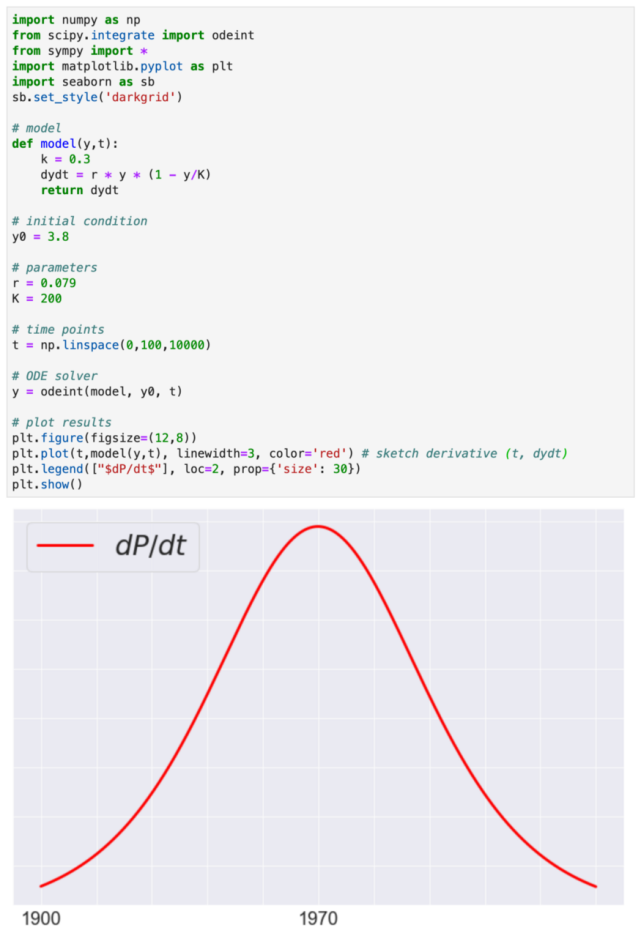
绘制 dP/dt 对 t 的曲线:
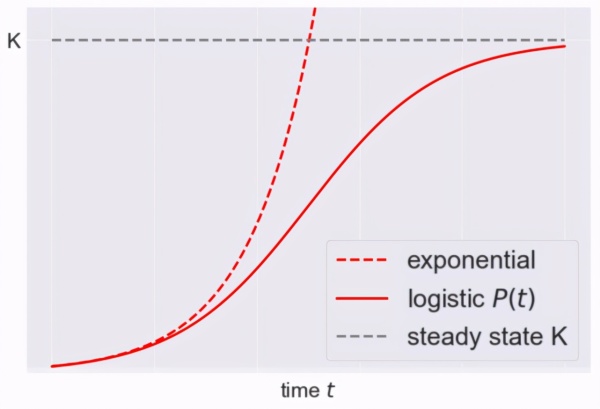
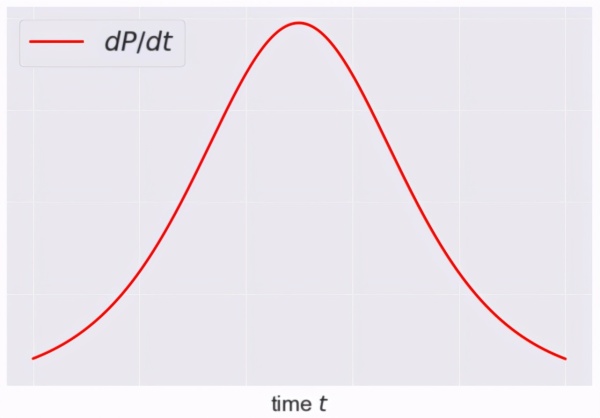
logistic 模型的一个例子是哈伯特峰值石油模型。1956 年,石油地质学家 Marion Hubbert 为德克萨斯州的石油生产量创建了一个预测数学模型。
令 P 表示德克萨斯州的产油量。
如果右边是 rP,则石油生产量将会成倍增长。但是 Hubbert 知道油量一共只有 K=200 gigabarrels。随着时间的流逝,开采石油变得越来越困难,因此生产率 dP/dt 有所下降。(1-P/K) 项说明了资源有限的观察结果。注意,在考虑实际数据之前,我们就已经推断出石油开采的机制。
代表生产率的参数 r=0.079 是从 50 年的数据中推断出来的。
代表石油总量的参数 K=200,这是系统的稳定状态。
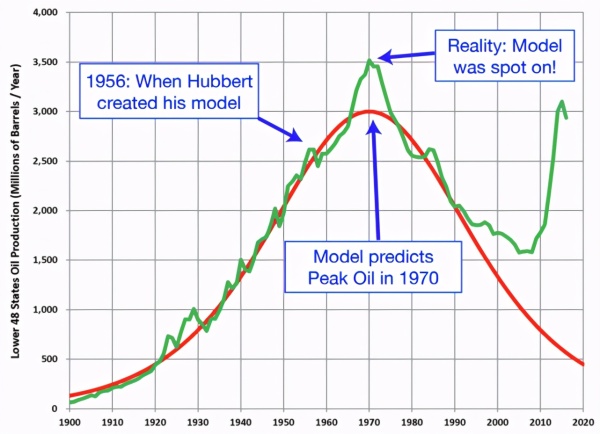
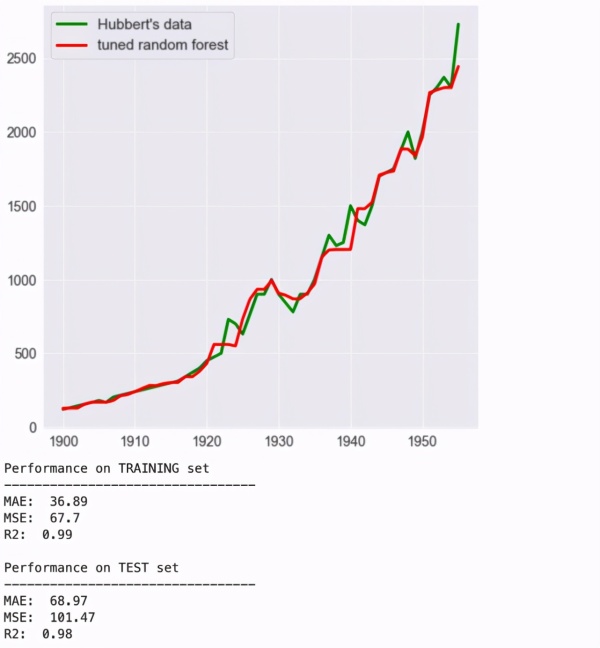
机器学习模型很难学习嵌入到微分方程中的逻辑所捕获的潜在机制。从本质上讲,任何算法都需要仅基于 1956 年之前存在的数据(绿色)预测能够出现的最大值:
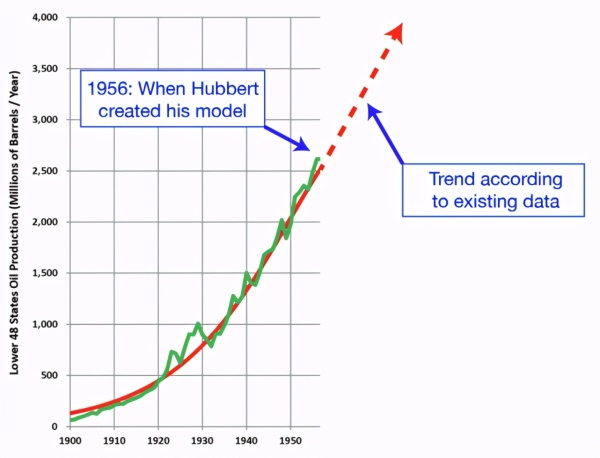
完整起见,本文作者训练了一些多项式回归、随机森林、梯度提升树。注意只有多项式回归会外推超出原始数据范围。

随机森林

多项式回归

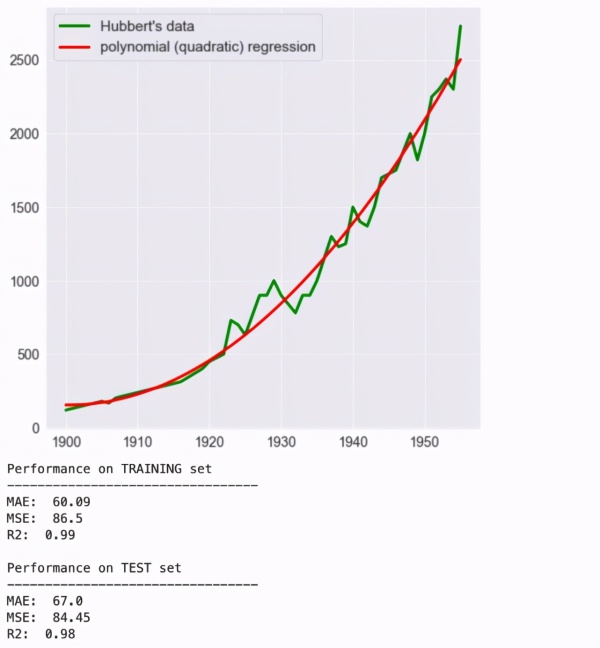
多项式回归可以很好地捕获信号,但是这种二次函数(图像为抛物线)在 1970 年达到 Peak Oil 之后,不可能再度凹回去。红色曲线只会越来越高,表示采油量接近无穷大。
哈伯特的机械模型解决了这一建模难题。
当人类很难捕捉和定义系统的规则和机制时,机器学习方法就会大放异彩。也就是说,从噪声中提取信号的方法超出了人们的努力范畴,更好的方法是让机器通过使用高质量示例来学习规则和信号,这就是用数据训练机器。数据越好,结果就越好。神经网络作为学术和应用机器学习领域的先锋,能够捕捉到惊人的复杂性。
求解 logistic 微分方程,并绘制 P(t) 和 P’(t)
上文介绍了 logistic 微分方程,并立即绘制了其解 P(t) 及其导数 dP/dt。这中间省略了一些步骤,详细操作方法如下。
方法 1:数值模拟
首先将微分方程编程到 Python 或 Matlab 中,在将 dP/dt 绘制为 t 的函数之前,使用数值求解器获得 P(t)。此处使用了 Python。
方法 2:获取解析解
该系统可以使用分离变量法求得解析解。请注意:大多数微分方程无法求得解析解。对此,数学家一直在寻找求解析解的方法。以新西兰科学家 Roy Kerr 为例,他发现了爱因斯坦场方程的一组精确解,进而使人类发现了黑洞。但还好,logistic 微分方程中有一些是具有确切解的。
首先把所有含有 P 的项移到等式左边,含有 t 的项移到等式右边:
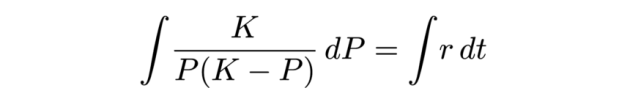
将二者整合到一起可得到通解,即满足微分方程的一组无穷多个函数。
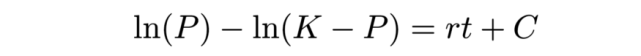
微分方程总是有无穷多个解,由一系列曲线以图像的方式给出。
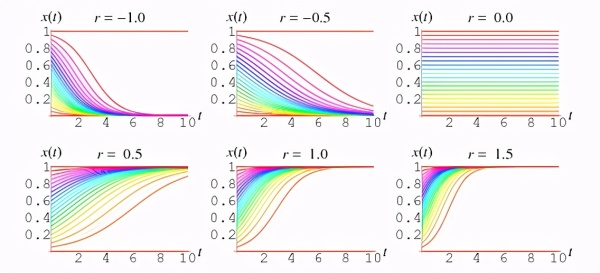
将 P 重新排列,得到:
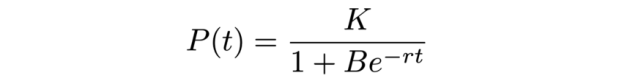
微分得到:
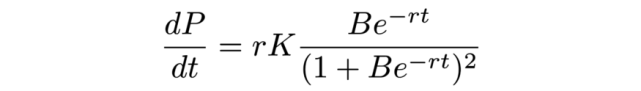
这两个公式对应上述 logistic 曲线和类高斯曲线。
总结
在机械建模中,对驱动系统的基本机制进行假设之前,研究者会仔细观察并研究现象,然后用数据验证模型,验证假设是否正确。如果假设正确,皆大欢喜;如果错误,也没关系,建模本身就是要反复试验的,你可以选择修改假设或者从头开始。
在数据驱动的建模中,我们让数据来构建系统的蓝图。人类要做的是为机器提供高质量、有代表性并且数量足够多的数据。这就是机器学习。在人类难以观察到现象本质时,机器学习算法可以从噪声中提取信号。神经网络和强化学习是当下热门的研究领域,它们能够创建具有惊人复杂性的模型。而 AI 革命尚在继续。
作者:佚名_机器之心Pro
原文链接:https://www.toutiao.com/i6898936761574031883/
转载请注明:www.ainoob.cn » 微分方程VS机器学习,实例讲解二者异同






