本文转载自公众号“读芯术”(ID:AI_Discovery)
我的这篇文章不是第一篇(也不会是最后一篇)讨论人工智能界如何按自身规律发展的文章。正如不久前汉娜·克纳(Hannah Kerner)的话:“很多AI研究人员认为现实世界中的问题无关紧要。社区过度关注新方法,却忽略了真正要紧的事情。”

许多大型会议公然忽视了应用型论文,这些文章聚焦于使用目前的技术解决现实世界中的问题,其中很多文章还关注在此过程中面临的挑战。程序是虚无缥缈的,目标检测额外精准10%,远比减少癌症死亡的1%更有价值。
人工智能界忽略了一个显而易见的事实:深度学习是一门实验科学。虽然神经网络脉络清晰,但它是一个难以解释的庞大的非线性系统。尽管越来越多的研究致力于阐释神经网络,但神经网络依然像以前一样神秘。科学方法是我们理解神经网络的唯一可靠工具,因为它植根于实验。
而矛盾之处在于,尽管神经网络的本质是实验,但是这个领域却拒绝纯粹的实验。一般,一篇神经网络的论文首先介绍其新颖之处,然后尝试形式证明,接着做消融研究,最后得出结论。这是根据实验得出的结论。
想象一下,如果土木工程师们决定创造与众不同的桥梁设计,却选择在桌子大小的乐高复制品上进行验证。没有使用真实建筑材料进行昂贵的仿真模拟或试验,你敢相信新提出的设计方案吗?你会特别信任这些实验,然后投资数百万美元来实现它们吗?不管你敢不敢,反正我是不敢。
简化的世界模型对于快速构建原型和尝试想法非常有用。但为了实际验证,你需要在真实的世界中进行尝试。这是一个两步走的过程。
现代AI研究停滞在前半段——基准这一问题上,实际的使用案例是后半段。ImageNet、COCO、CIFAR-10,这些都是人工智能的乐高。它们让我们实验新的想法,摒弃不佳的构思,它们是很好的工具。然而,它们只是达到目的的一种手段,而不是目的本身。
这并不是说当前的研究是错的,关键问题在于学术界与现实世界之间的脱节。
看看这个图表:该图介绍了COCO目标检测基准的最新进展,每一个小点都是一个不同的模型——一种新技术或现有技术的融合,领跑者用蓝色标出。
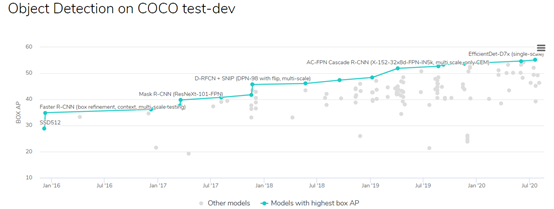
COCO测试开发排行榜上带有编码的论文
该图表显示了从2016年1月的28.8点到2020年7月的55.1点的轨迹。取得的进步是无可否认的,从图中可以看出,EfficientDet D7x是目前最好的目标检测技术。但是,问你一个问题:你会在应用程序中使用哪一个模型?
你很可能无法作答,因为你不知道我说的是哪个应用程序,也不知道它有哪些要求。它需要实时运行吗?它能在移动设备上运行吗?它需要识别多少类?用户对错误检测的容忍度有多大……
依据答案,以上这些都不值得考虑,甚至连EfficientDet D7x都不值得考虑。如果模型必须在手机上实时运行,那么即使略微调整这些模型,也执行不了。更糟糕的是,不能保证这些模型能在连续帧之间产生一致的检测结果。我甚至不能说出一个要求最高检测质量的应用程序的名字,除了高准确度之外,没有其他要求。
换句话说,科研界所追求的度量标准只用于研究其本身。
早在2015年,研究发现,神经网络的深度增加超过12层会对性能造成损害。在著名的残差网络(ResNet)论文(https://arxiv.org/abs/1512.03385)中,何凯明博士以及其他几位学者假设通过跳过连接,连接非连续层可以扩大容量,因为它可以提升梯度流。
第一年,ResNet在几个基准竞赛中取得了优异的成绩,如ILSVRC和COCO。但你现在应该已经意识到了这只暗示ResNet是一个重要贡献,但这不是证据。
ResNet在人工智能历史上的地位的确切证据是建立在其大量工作上的。ResNet的惊人之处在于它解决不相关问题的数量,而不在它获胜的竞争。它真正的贡献在于这个跳过连接的想法,而不是架构本身。
这篇有关Focal Loss(https://arxiv.org/abs/1708.02002)的论文同样经受住了时间的考验,确实改进了他人的研究。这篇关于Attention的论文(https://arxiv.org/abs/1706.03762)也遵循同样的路线。每天都有一篇新文章讨论Attention是如何提高某些基准的,以及聚集损失让Attention变得更好。
重要的不是竞赛,而是之后的影响。事实上,2012年ILSVRC的冠军是AlexNet,而2015年的冠军是ResNet。你能说出2013年和2014年的获胜者吗?2016年、2017年和2018年的挑战是什么?你能确保每年都举办ILSVRC吗?
你可能会问:为什么没有更好的基准或更有用的度量标准?我们如何衡量后继影响?
遗憾的是,我们做不到。我们可以使用引用或下载的计数,Reddit的访问量或者GitHub的星号标注。然而,这些度量标准都是有瑕疵的。为了进行公平的比较,我们需要考虑到每一个细节,同时从等式中将所有的偏差进行标准化处理,这太难了。
例如,为了比较Attention和ResNet的影响力,我们需要考虑正确使用这些概念,权衡它们的相对影响,并将时间和影响范围进行标准化处理。很明显,量化这些属性的工作量巨大,可能与所有基准或度量标准一样有缺陷。诸如杂志的影响因素之类的想法甚至没有触及这个问题的表面。
有些目标是无法量化的。谁是最有声望的人?是西方音乐史上最具影响力的作曲家巴赫,还是最具影响力的剧作家莎士比亚?比较他们的作品毫无意义,更不用说他们的领域了。

巴赫还是莎士比亚,音乐还是戏剧?
这就走进了死胡同。我们可以测量精确度,可以测量速度,但是无法判定影响力。我们都承认我们需要更先进的科学,但是我们如何断定一种科学比另一种科学更好呢?我们如何衡量研究和现实之间的脱节?我们希望能和人工智能一起前进,但是我们既不知道前进的方向,也不知道已经走了多远。
这不仅仅是人工智能的问题。我们想要更健全的政府,更完善的医疗服务,更优质的教育,但是怎样才能真正量化这些呢?到目前为止,最失败的方法(也是最普遍的方法)是替代度量,比如COCO AP的得分。
我们无法衡量人工智能的进步,但我们可以测量目前的目标检测方法有多精准。目标检测也是AI的一部分,所以,如果能在这方面取得一些进展,我们也可以期待在人工智能方面取得进展。
在我们确定使用COCO之前,我们一直使用ImageNet前5名的结果,所以面临一个更具挑战性的问题。我们无法通过训练检测模型来提高AP,但是可以教会它们减少边界盒坐标的L2损失。损失是不可微度量的替代。L2损失不是AP,但低L2损失与高AP相关,所以它是有效的。
从前,识字率是许多国家衡量教育进步的主要指标。几十年后,在识字率非常高的情况下,更高的学业完成率便是衡量教育进步的重点。然后是更高的大学入学率。我不知道学位与教育之间的关系是否像我们想象的那样紧密,也不知道高中教的知识是不是他们应该教的,但这是我们今天追求的指标。
从某种意义上说,对于这些问题,没有什么解决方法是对的。因此,根据定义,所有的路线都是错误的。只有尽可能多的尝试各种途径,我们才有可能选择一条相对正确的道路。使用AI术语,我们需要使用更大的批量抓取,并对尽可能多的分布进行采样。
这意味着我们必须将关注范围扩大到“准确性”和“速度”之外,还要包括“稳健性”或“连贯性”等内容。最重要的是,我们需要从精心挑选的基准转向现实世界。
以我研究乳腺癌检测算法的案例为例,研究员很容易错将这个领域当成已解决的领域。最近的研究已经在这个主题上取得了超人的成绩,但是,这些算法却无法应用于任何一家医院。原因很简单,它并不起作用。
这听起来有些夸张,但其实非常简单:即使是同一种东西,即乳房x光片,如果你在数据集a上训练算法,算法不会在数据集B上工作。
目前没有已知的技术可以在不进行微调的情况下,在数据集上进行训练,并在其他数据集上运行良好。你必须针对每台机器/每家医院建立数据集,以获得有用的结果。度量标准合理,这个领域就解决了。实际上,这连开始都难。
最重要的是,算法无法为他们的答案提供帮助。站在医生的角度想想:你会因为机器是这样显示的,就告诉患者他们得了癌症吗?你不会,你会再次查看这些图像。
如果人们不信任人工智能,那么就永远不会使用它。
到目前为止,已发表的论文的主要评判标准是AUC评分。它告诉你该算法对乳房x光片的良恶性分类有多合理,不会告诉你它对其他数据集有多稳健,或者所有都是可解释的。换句话说,它从不回答“它有用吗”这类问题。
发展人工智能没有正确的道路,但肯定有非常错误的道路。花不了太多的时间,你就能发现大多数文献有多不适用,以及真正紧迫的问题是如何堂而皇之的被人们忽视了。
正如我在开头所说的,这篇文章并不要指责当前的研究不好,而是说问题的关键在于当前学术界和现实世界之间脱节——我们过于狭隘地关注准确性。
发展人工智能不是为了纸上谈兵,推动社会发展是真正重要的事,我们希望通过改善人工智能来实现这一点。但只有当我们正视现实的社会问题时,我们才能正确地做到这一点。社会的问题远比精确的目标检测更复杂

作者:读芯术_读芯术
原文链接:https://www.toutiao.com/i6875595885623902723/
转载请注明:www.ainoob.cn » 标准出现问题,人工智能正在走向错误的方向






