深度神经网络(DNN)本质上是通过具有多个连接的感知器而形成的,其中感知器是单个神经元。可以将人工神经网络(ANN)视为一个系统,其中包含沿加权路径馈入的一组输入。然后处理这些输入,并产生输出以执行某些任务。随着时间的流逝,ANN“学习”了,并且开发了不同的路径。各种路径可能具有不同的权重,并且在模型中,比那些产生较少的理想结果的路径,以及被发现更重要(或产生更理想的结果)的路径分配了更高的权重。
在DNN中,如果所有输入都密集连接到所有输出,则这些层称为密集层。此外,DNN可以包含多个隐藏层。隐藏层基本上是神经网络输入和输出之间的点,激活函数对输入的信息进行转换。之所以称其为隐藏层,是因为无法从系统的输入和输出中直接观察到这一点。神经网络越深,网络可以从数据中识别的越多,输出的信息越多。
但是,尽管目标是从数据中尽可能多地学习,但是深度学习模型可能会遭受过度拟合的困扰。当模型从训练数据(包括随机噪声)中学习太多时,就会发生这种情况。然后,模型可以确定数据中非常复杂的模式,但这会对新数据的性能产生负面影响。训练数据中拾取的噪声不适用于新数据或看不见的数据,并且该模型无法概括发现的模式。非线性模型在深度学习模型中也非常重要,尽管该模型将从具有多个隐藏层的内容中学到很多东西,但是将线性形式应用于非线性问题将导致性能下降。
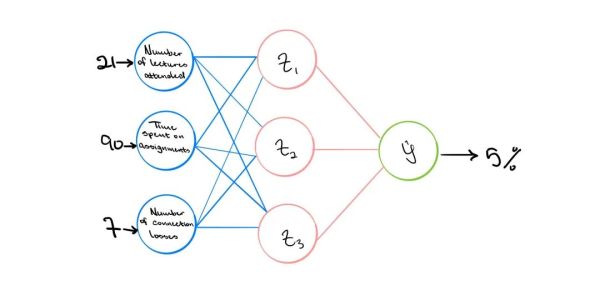
现在的问题是,“这些层如何学习东西?” 好吧,我们可以在这里将ANN应用于实际场景以解决问题并了解如何训练模型以实现其目标。案例分析如下:
在当前的大流行中,许多学校已经过渡到虚拟学习,这使一些学生担心他们通过课程的机会。“我将通过本课程”这个问题是任何人工智能系统都应该能够解决的问题。
为简单起见,让我们考虑该模型只有3个输入:学生参加的讲座的数量,在作业上花费的时间以及整个讲座中互联网连接丢失的次数。该模型的输出将是二进制分类。学生要么通过了课程,要么没有通过,其实就是0和1。现在到了学期期末,学生A参加了21堂课,花了90个小时进行作业,并且在整个学期中有7次失去互联网连接。这些输入信息被输入到模型中,并且输出预测学生有5%的机会通过课程。一周后,发布了最终成绩,学生A通过了该课程。那么,模型的预测出了什么问题?
从技术上讲,没有任何问题。该模型本来可以按目前开发的方式工作。问题在于该模型不知道发生了什么。我们将在路径上初始化一些权重,但是该模型当前不知道对与错。因此,权重不正确。这就是学习的主要源头,其中的想法是模型需要掌握错误的时间的规律,我们通过计算某种形式的“损失”来做到这一点。计算得出的损失取决于当前的问题,但是通常会涉及使预测输出与实际输出之间的差异最小化。

在上述情况下,只有一名学生和一个错误点可以减少到最小。但是,通常不是这种情况。现在,如果考虑将多个学生和多个差异最小化,那,总损失通常将计算为所有预测和实际观察值之间的差异的平均值。
回想一下,正在计算的损失取决于当前的问题。因此,由于我们当前的问题是二元分类(0和1分类),因此适当的损失计算将是交叉熵损失,该功能背后的想法是,它比较学生是否将通过课程的预测分布与实际分布,并尝试最小化这些分布之间的差异。
取而代之的是,我们不再希望预测学生是否会通过该课程,而是希望预测他们将在该课程中获得的分数。因此,交叉熵损失将不再是一种合适的方法。相反,均方误差损失将更合适。此方法适用于回归问题,其思想是将尝试最小化实际值和预测值之间的平方差。

现在我们了解了一些损失函数(这里有损失函数的介绍:深度学习基础:数学分析基础与Tensorflow2.0回归模型 文章末尾可下载PDF书籍),我们可以进行损失优化和模型训练。拥有良好DNN的关键因素是拥有适当的权重。损耗优化应尝试找到一组权重W,以最小化计算出的损耗。如果只有一个重量分量,则可以在二维图上绘制重量和损耗,然后选择使损耗最小的重量。但是,大多数DNN具有多个权重分量,并且可视化n维图非常困难。
取而代之的是,针对所有权重计算损失函数的导数,以确定最大上升的方向。现在,模型可以理解向上和向下的方向,然后向下移动,直到达到局部最小值的收敛点。完成这一体面操作后,将返回一组最佳权重,这就是DNN应该使用的权重(假设模型开发良好的话)。
计算此导数的过程称为反向传播,它本质上是来自微积分的链式法则。考虑上面显示的神经网络,第一组权重的微小变化如何影响最终损失?这就是导数或梯度试图解释的内容。但是,第一组权重被馈送到隐藏层,然后隐藏层又具有另一组权重,从而导致预测的输出和损失。因此,还应考虑权重变化对隐藏层的影响。现在,这些是网络中仅有的两个部分。但是,如果要考虑的权重更多,则可以通过应用从输出到输入的链式规则来继续此过程。
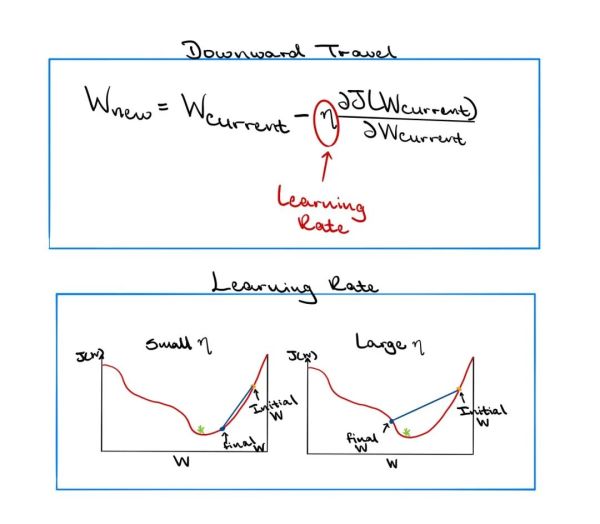
训练DNN时要考虑的另一个重要因素是学习率(可以看做是数学中的收敛因子)。当模型行进以找到最佳的权重集时,它需要以某种因素来更新其权重。尽管这似乎微不足道,但是确定模型移动的因素非常非常必要。如果因子太小,则该模型可以运行一段指数级的长时间,也可以陷入非全局最小值的某个位置。如果因数太大,则模型可能会完全错过目标点,然后发散。
尽管固定比率可能是理想的,但自适应学习比率会减少前面提到的问题的机会。也就是说,该系数将根据当前梯度,当前权重的大小或其他可能影响模型下一步来寻找最佳权重的地方而变化。

可以看出,DNN是基于微积分和一些统计数据构建的。评估这些深度技术过程背后的数学思想是有用的,因为它可以帮助人们了解模型中真正发生的事情,并且可以导致整体上开发出更好的模型。
作者:人工智能科技时代_今日头条
原文链接:https://www.toutiao.com/a6872733464353833472/
转载请注明:www.ainoob.cn » 分析深度学习背后的数学思想





