人工智能正在做不可思议的事情-驾驶汽车,调酒,打仗-但是,尽管机器人面具受到了沉重的关注和关注,但任何真正的技术爱好者都知道基本的机器学习算法,这些算法可以移动并控制可实现惊人成就的机器人技术。

有四种主要的机器学习算法-决策树,随机森林,支持向量机和神经网络-在最近的AI开发中常用。 机器人技术背后的算法甚至比机器本身重要得多,更不用说机器学习的非物理应用了。
机器学习基础
机器学习由多个领域组成,其中与人工智能应用最相关的一个领域是监督学习。 在机器学习的这一部分中,算法被赋予x并被告知预测y。 在自动驾驶汽车的应用中,x可能是当前汽车前方的图像。 我们将假定图像像素为700像素宽,400像素长,它们将形成700 * 400 = 280,000尺寸的x。
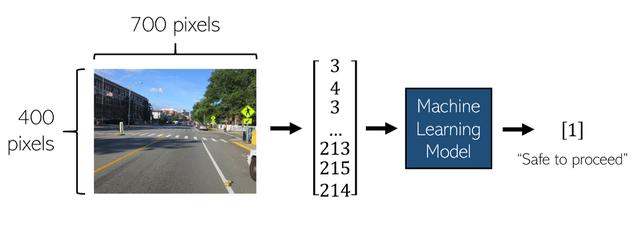
在上面的示例中,前方道路的图像被转换为长度为280,000的矢量,然后将其输入经过训练的机器学习模型中。 在这种情况下,模型可能会输出1表示”行进安全”(如果认为道路行进不安全,则输出0)。 自动驾驶汽车中图像识别的其他领域包括深度感知(识别物体有多远)或读取限速标志。 除了图像分类之外,机器学习的其他应用程序还包括确定计算一个人过街的速度或确定前方汽车向右转的可能性。
在文本实例中,文本被矢量化或转换为数字数组。 文本可以被分类,例如在真实/伪造新闻中,或用于生成(创建唯一文本)。
机器学习算法输入和输出的所有内容都是纯数字的,因此每种算法本质上都是数学的。 机器学习算法只需执行一组数学过程即可将多维x数据转换为(通常)奇异的y值。 监督学习的主要子类是分类和回归。 前者致力于将x划分为一组离散的类别(例如,图像是猫还是狗),而后者则致力于以连续的比例分配xay(例如,基于诸如卧室数量等属性的房价) 。
数据的每个维度也称为要素。 在图像的情况下,每个像素都是一个特征,或者在预测房价的示例中,每个房屋属性(例如,卧室,浴室的数量,是否有水滨等)都是一个特征。
决策树
决策树算法基于以下简单思想:遵循一组是/否问题以得出最终结论。 例如,一个例子是问一个朋友接下来要尝试哪种食物。 您的朋友可能会根据他们的经验问您一系列”是/否”问题,以确定您应该尝试哪种食物。 示例树可能如下所示:
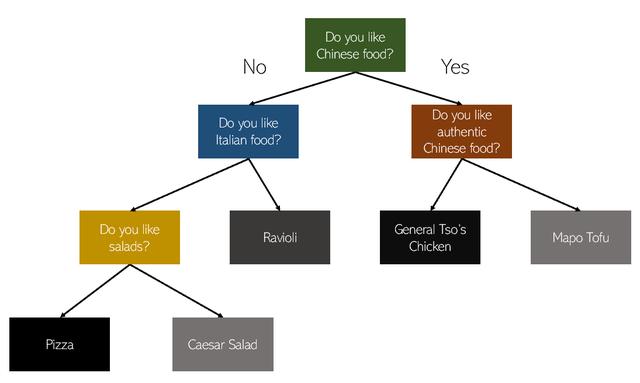
根据您对朋友问题的是/否回答,您的朋友沿着树下的路径到达终点。 对于真实数据集,决策树可能深达数十层。 决策树在分类方面非常强大。 在数据集中,算法尝试通过将最有区别的特征放在顶部来构造树。 最具特色的功能是提供最多信息的最佳功能。
一个功能的”好”程度可以通过其信息增益来衡量,也可以通过仅基于该功能将数据分为两类来提供多少信息。
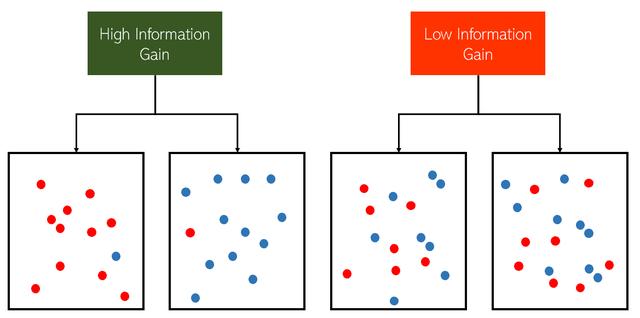
决策树的各层在顶部添加了最多的信息获取功能,在底部添加了最少的信息获取功能。 在实际数据集中,决策树仍会构造是/否问题,但可以用许多方式来表达它们,例如:
- 浴室数量是否大于或等于3?
- 房子在水边吗?
决策树算法还可以通过较小的方式用于回归,也可以提供概率置信度(基于获得的信息量)。 决策树可以通过复杂的数据结构选择方法,但也可以解释。 决策树可用于诊断癌症,阿尔茨海默氏症或相关的医疗状况。 他们能够捕捉人类医生永远无法完成的复杂性和深度。
随机森林
决策树可以使用随机森林算法进行改进。 决策树的问题在于,由于它们试图最大程度地获取信息,因此很容易过度拟合。 此时,模型变得非常擅长对数据进行分类,以致于无法在将要使用的新数据上很好地表现数据。 这类似于孩子记住对问题的确切措词的确切答案,但不能回答具有不同措辞的问题。
在机器学习中,决策树被认为是高偏置算法。 就像您的朋友推荐尝试食物的类比,仅一个朋友一个人就会使您有偏颇的选择。 随机森林通过在”森林”中包含多个决策树模型来扩展决策树算法。
类似于一个朋友推荐食物的例子,想象一下问十个不同的朋友来指导您完成相同的是/否问题解答过程。 由于每个朋友都有不同的口味和经验,因此他们会提出不同的问题,并得出自己应该尝试哪种食物的结论。 最后,您选择十个朋友中大多数同意您应点的食物。 这样可以做出更全面的决策,而不仅仅是基于一个朋友,而是从许多人的全球角度出发。
随机森林算法包括许多决策树。 每个人都接受数据的不同子集的训练,这些子集都是随机选择的。 每个模型都在不同的数据子集上进行训练,类似于具有不同的体验和品味。 在每个子集上构建决策树之后,随机森林模型会汇总其投票以得出最终决策。
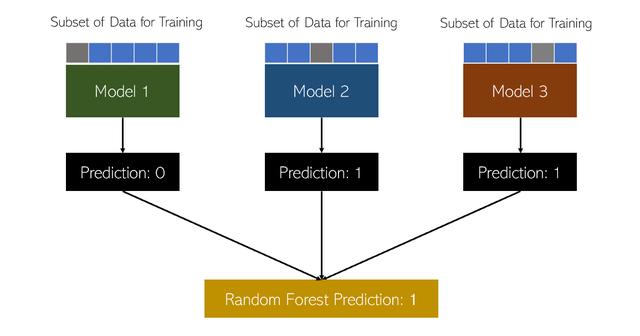
随机森林模型可以执行决策树算法可以完成的相同任务。 其优点在于,它可以提供更平衡的透视图,但训练起来的计算量也更大。 在某些情况下,随机森林甚至可能比决策树更差。 无论如何,决策树和随机森林都是非常强大的分类算法,在AI中有许多应用。
支持向量机(SVM)
支持向量机(SVM)算法是机器学习中用于二进制分类(将数据点分为两类之一)的一种常用且功能强大的算法。 SVM算法构造一条线,将数据分为两类,如下所示。
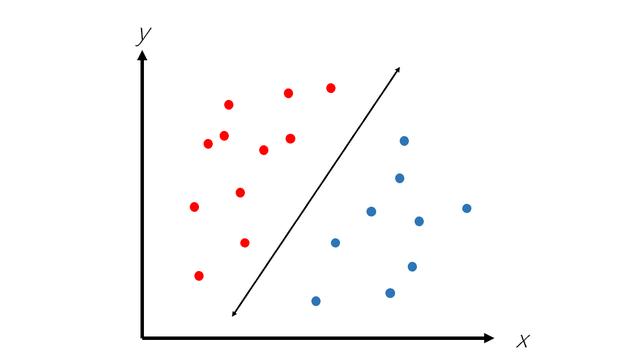
但是,SVM的前提是数据是线性可分离的,这意味着可以将它们放在带有直线(或超平面)的两个不同类别中。 然而,这并非总是如此:
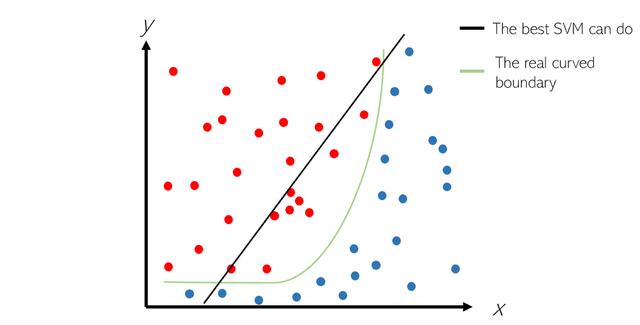
在这种情况下,纯线性SVM分隔符无法容纳真实的弯曲边界。 因此,为了解决皮肤问题,SVM应用了各种内核函数以在可线性分离的边界之间拉直数据。 尽管这是一个简化,但这是内核技巧的主要思想。 例如,考虑指数边界,并且应用对数对拉直的效果。
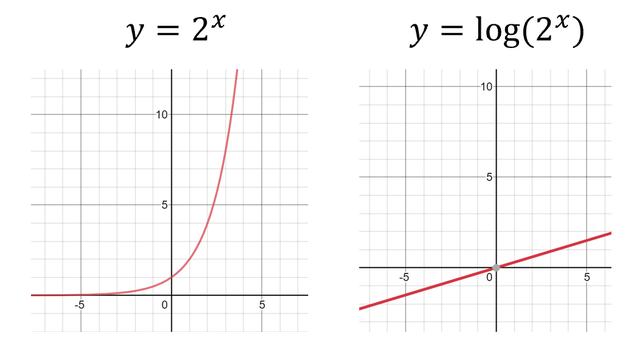
还将训练适用于数据的哪些函数,包括但不限于多项式,S形,高斯函数以及这些函数的任意组合,以提供最容易线性分离的数据。 在高维数据中,无论数据的结构如何,SVM都可以很好地运行。
支持向量机有时被用作低维图像分类的一种低计算成本的方法,该模式易于识别,因此支持向量机可以正确地对其进行分类,但不能保证复杂数据关系的常用算法即神经网络。
神经网络
神经网络是机器学习中最强大的算法家族。 但是,数学上已经证明,没有”通用”算法可以在所有数据集上发挥最佳性能,因此,不应将神经网络用作对任何数据集的切刀解决方案。 最重要的是,它们的培训成本可能很高,因此应谨慎使用。
就是说,神经网络是最先进的AI应用程序中使用最广泛的算法。 它们在大脑中模拟神经元及其之间的联系。 在神经网络中,存在三种类型的层:
- 输入图层,用于接收信息。 输入层中神经元的数量与输入(X)的维数相对应。 例如,如果图像数据集为28 x 28像素,则输入层将具有28 x 28 = 784个神经元。
- 输出层,输出神经网络的决策。 输出层中神经元的数量与输出的维数(y)相对应。 例如,一个旨在将新闻分类为真实(1)或伪造(0)的数据集将只有一个输出神经元。
- 隐藏层,它们连接输入层和输出层。 隐藏层为神经网络增加了更多的复杂性和信息。 通常,隐藏层越多,神经网络可以执行的功能越复杂和”智能”。
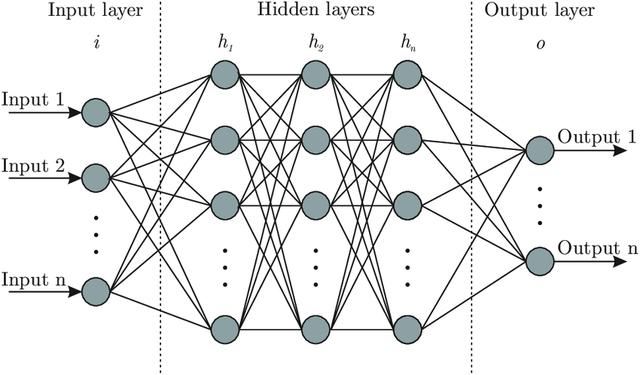
每个神经元就像一个小型计算器-信息经过传递,转换,然后传递到下一层。 神经元具有输入要通过的激活函数,该函数将输入简单地转换为更好地帮助神经网络理解和处理信息的格式。
神经元之间的每个连接也具有权重。 信息通过连接传递时,将乘以权重。
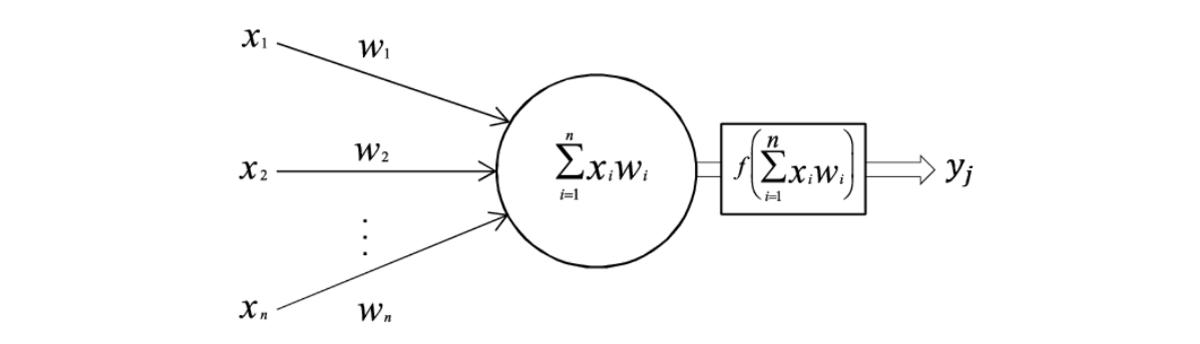
每个神经元都会执行少量计算,将它们与权重链接在一起时,现代神经网络便会在庞大的规模上运行-数十个隐藏层,每层数百个神经元以及数百万个参数(权重),它们可以生成文本, 读取图像并执行其他”智能”操作。
神经网络的反向传播算法可调整权重。 在神经网络中,调整神经网络之间的权重。 如果网络足够大,可能要花费数小时甚至数天的时间来训练几千万个砝码中的每一个。
神经网络和深度学习一直是最新技术发展背后的算法,其中包括AlphaGo击败世界围棋冠军,创造逼真的艺术品并产生音乐。
现在您了解了AI的引擎。
谢谢阅读! 如果您对AI中的这四种算法或机器学习有任何疑问或澄清,请随时做出回应。
作者:闻数起舞_今日头条
原文链接:https://www.toutiao.com/i6831355917661897219/






