如何处理机器学习中偏斜的数据集
用偏斜的数据集开发有效的机器学习算法可能很棘手。例如,数据集涉及银行中的欺诈活动或癌症检测。发生的情况是,您将在数据集中看到99%的时间没有欺诈活动或没有癌症。您可以很容易地作弊,并且始终可以仅预测0(如果癌症则预测1,如果没有癌症则预测0),从而获得99%的准确性。如果这样做,我们将拥有99%的准确机器学习算法,但我们将永远不会检测到癌症。如果某人患有癌症,他/他将永远得不到治疗。在银行中,不会采取任何针对欺诈活动的措施。因此,仅靠准确性就无法确定偏斜的数据集,就像算法是否有效运行一样。

背景
有不同的评估矩阵可以帮助处理这些类型的数据集。这些评估指标称为精确召回评估指标。
要了精确度和召回率,您需要了解下表及其所有术语。考虑二进制分类。它将返回0或1。对于给定的训练数据,如果实际类别为1,而预测类别也为1,则称为真实肯定。如果实际类别为0,而预测类别为1,则为假阳性。如果实际类别为1,但预测类别为0,则称为假阴性。如果实际类别和预测类别均为0,则为真阴性。
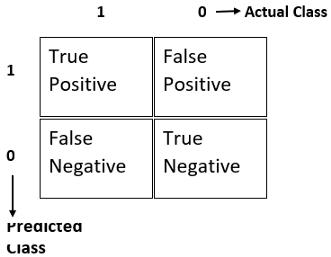
使用所有这些,我们将计算精度和召回率。
精确
Precision会计算出我们预测为欺诈的交易(预测为1类)中有多少实际上是欺诈的。可以使用以下公式计算精度:
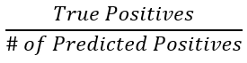
进一步分解,该公式可以写成:
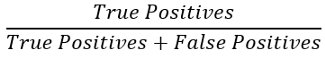
从公式中可以看出,更高的精度是好的。因为更高的精度意味着更多的真实肯定。这意味着当我们说此交易是欺诈性的时,这是事实。
召回
回忆告诉我们,最初欺诈的所有交易中有多少被检测为欺诈。这意味着,如果我们告知银行适当的权力采取行动,那么在某笔交易实际上是欺诈的情况下。当我第一次阅读这些关于精确度和召回率的定义时,我花了一些时间才能真正理解它们之间的区别。我希望你能更快地得到它。如果没有,那就不用担心。你不是一个人。
召回率可以通过以下公式计算:

用上面2 x 2表中定义的术语表示:
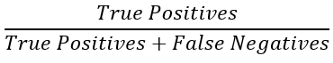
从精确度和召回率做出决策
精确度和召回率可以更好地了解算法的实际运行方式,尤其是在数据集高度偏斜的情况下。如果我们一直预测为0并获得99.5%的准确度,则召回率和精确度都将为0。因为没有真正的肯定。因此,您知道分类器不是一个好的分类器。当精度和查全率都很高时,表明该算法运行良好。
假设仅在高度自信的情况下,我们要预测y = 1。因为有时候这很重要。特别是当我们处理医疗数据时。假设我们正在检测某人是否患有心脏病或癌症。预测假阳性会给一个人的生活带来很多痛苦。提醒一下,通常,逻辑假设如果假设大于或等于0.5,则预测1;如果假设小于0.5,则预测0。
- 如果假设≥0.5,则预测1
- 如果假设<0.5,则预测0
但是,当我们如上所述处理某些敏感情况时,我们想更确定自己的结果,如果假设≥0.7,我们将预测为1,如果假设<0.7,我们将预测为0。如果您想对结果更有信心,可以看到0.9之类的值。因此,您将90%地确定某人是否患有癌症。
现在,看看精度和召回率公式。真实肯定和错误肯定都会更低。因此,精度会更高。但另一方面,由于我们现在将预测更多的负面因素,因此,假阴性的可能性会更高。在这种情况下,召回率会更高。但是太多的假阴性也不好。如果某人确实患有癌症,或者某个账户有欺诈行为,但是我们告诉他们他们没有癌症,或者该账户没有欺诈行为,则可能导致灾难。
为了避免误报并提高召回率,我们需要将阈值更改为以下内容:
- 如果假设≥0.3,则预测1
- 如果假设<0.3,则预测为0
与以前的情况相反,我们将具有更高的召回率和更低的精度。
那么如何确定阈值呢?这将取决于您的要求。根据数据集,您必须决定是否需要更高的精度或更高的查全率。这是精度调用曲线:
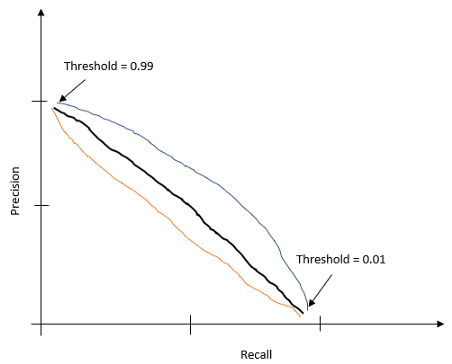
精确调用曲线可以是任何形状。因此,我在这里显示三种不同的形状。如果您不能自己决定是否需要更高的精度或更高的查全率,则可以使用F1分数。
F1分数
F1分数是准确性和召回率的平均值。但是平均公式却不同。常规平均公式在这里不起作用。看一下平均公式:
(精确+召回)/ 2
即使精度为0或召回率为零,平均值仍为0.5。请记住,从我们之前的讨论中可以看出,精度为零是什么意思。我们总是可以预测y =1。因此,这应该是不可接受的。因为整个精确调用的想法是避免这种情况。公式F1得分是:

在这里,P是精度,R是召回率。如果精度为零或召回率为零,则F1分数将为零。因此,您将知道分类器没有按照我们的期望工作。当精度和召回率都完美时,这意味着精度为1,召回率也为1,F1分数也将为1。因此,理想的F1分数是1。最好尝试使用不同的阈值并计算精度,召回率和F1分数,以找到适合您的机器学习算法的最佳阈值。
结论
在本文中,您学习了如何处理偏斜的数据集。如何使用F1分数在精确度和召回率之间进行选择。希望对您有所帮助。
作者:闻数起舞_今日头条
原文链接:https://www.toutiao.com/i6907426451298173451/
转载请注明:www.ainoob.cn » 免费Python机器学习课程八:精确度,召回率






