如今,人工智能程序可以识别照片和视频中的面部和物体,实时转录音频,提前数年通过X射线扫描检测癌症,并在某些最复杂的游戏中与人类竞争。

直到几年前,所有这些挑战要么被认为是无法克服的,几十年之遥,要么已经以次优的结果得以解决。但是神经网络和深度学习的进步是人工智能的一个分支,在过去几年中非常流行,它帮助计算机解决了这些问题以及许多其他复杂问题。
不幸的是,深度学习模型从头开始创建时,需要访问大量数据和计算资源。这是许多人买不起的奢侈品。而且,训练深度学习模型来执行任务需要很长时间,这不适合时间预算短的用例。幸运的是,转移学习是一种使用从一种训练有素的AI模型获得的知识到另一种知识的学科,可以帮助解决这些问题。
训练深度学习模型的成本
深度学习是机器学习的子集,是通过训练示例开发AI的科学。但是直到最近几年,由于效率低下,它们在很大程度上已被AI社区驳回。在过去的几年中,大量数据和计算资源的可用性使神经网络备受关注,并使开发能够解决现实世界问题的深度学习算法成为可能。
要训练深度学习模型,您基本上必须为神经网络提供大量带注释的示例。这些示例可以是诸如标有物体的图像或患者的乳房X线照片扫描及其最终结果之类的东西。神经网络将仔细分析和比较图像,并开发数学模型来表示相似类别图像之间的重复模式。
已经存在一些大型的开源数据集,例如ImageNet(一个包含22000个类别的超过1400万张图像的数据库)和MNIST(一个包含60000个手写数字的数据集)。AI工程师可以使用这些资源来训练他们的深度学习模型。
但是,训练深度学习模型还需要访问非常强大的计算资源。开发人员通常使用CPU,GPU集群或专用硬件(例如Google的Tensor处理器(TPU))来高效地训练神经网络。购买或租用此类资源的成本可能超出单个开发人员或小型组织的预算。而且,对于许多问题,没有足够的示例来训练强大的AI模型。
转移学习使深度学习培训的要求大大降低
假设AI工程师想要创建图像分类器神经网络来解决特定问题。工程师无需收集成千上万的图像,而可以使用诸如ImageNet之类的公共可用数据集,并使用特定领域的照片对其进行增强。
但是AI工程师仍然必须付出高昂的费用来租用通过神经网络运行这些数百万个图像所需的计算资源。这是转移学习发挥作用的地方。转移学习是通过微调先前受过训练的神经网络来创建新AI模型的过程。
开发人员无需从头开始训练他们的神经网络,而是可以下载经过预先训练的开源深度学习模型,并根据自己的目的对其进行微调。有许多预训练的基本模型可供选择。流行的示例包括AlexNet,Google的Inception-v3和Microsoft的ResNet-50。这些神经网络已经在ImageNet数据集上进行了训练。AI工程师只需要通过使用他们自己的特定领域的示例对它们进行进一步的培训来增强它们。
转移学习不需要大量的计算资源。在大多数情况下,一台台式计算机或一台笔记本电脑可以在几个小时甚至更少的时间内对预训练的神经网络进行微调。
转移学习如何工作
有趣的是,神经网络以分层方式发展其行为。每个神经网络都由多层组成。训练后,调整每个图层以检测输入数据中的特定特征。
例如,在图像分类器卷积网络中,前几层检测一般特征,例如边缘,拐角,圆形和颜色斑点。随着您深入网络,这些层开始检测更具体的事物,例如眼睛,面部和完整的物体。

神经网络的顶层检测一般特征。更深的层检测实际对象(来源:arxiv.org)
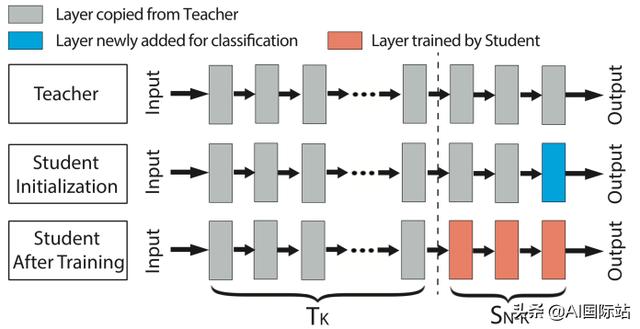
在进行迁移学习时,AI工程师冻结了预训练神经网络的第一层。这些是检测所有域共有的常规功能的层。然后他们微调更深的层,以使用自己的示例对它们进行微调,并添加新层以对训练数据集中包含的新类别进行分类。
经过预先训练和微调的AI模型也分别称为“教师”模型和“学生”模型。
冻结层和微调层的数量取决于源AI模型和目标AI模型之间的相似性。如果学生AI模型解决了非常接近老师的问题,则无需微调预训练模型的各个层次。开发人员仅需在网络末端添加一个新层,并为新类别训练AI。这称为“深层特征提取”。当目标域的训练数据很少时,深度特征提取也更可取。
当源与目的地之间存在相当大的差异,或者培训示例很多时,开发人员将冻结预训练的AI模型中的几层。然后,他们添加新的分类层,并使用新示例微调未冻结的层。这称为“中间层特征提取”。
如果源AI模型和目标AI模型之间存在显着差异,则开发人员将取消冻结并重新训练整个神经网络。这种称为“完整模型微调”的转移学习还需要大量的训练示例。
图片来源:芝加哥大学
采取预训练的模型并重新训练其所有层似乎是荒谬的。但实际上,它可以节省时间和计算资源。在训练之前,神经网络中的变量将使用随机数进行初始化,并在处理训练数据时调整其值。预训练神经网络的变量值已被调整为数百万个训练示例。因此,它们对于新的AI模型来说是一个更好的起点,该模型想要训练一组与源AI模型甚至有一点相似之处的新示例。
转移学习不是灵丹妙药
转移学习解决了以有效且负担得起的方式训练AI模型的许多问题。但是,它也需要权衡。如果预训练的神经网络存在安全漏洞,则AI模型会使用它作为迁移学习的基础,并继承这些漏洞。
例如,基本模型可能无法抵抗对抗攻击,精心设计的输入示例会迫使AI以不稳定的方式更改其行为。如果恶意行为者设法为基本模型开发对抗示例,则他们的攻击将对从其派生的大多数AI模型起作用。芝加哥大学,加州大学圣塔克拉拉分校和Virgina Tech的研究人员在去年Usenix安全研讨会上发表的一篇论文中对此进行了说明。
此外,在某些领域,例如教AI玩游戏,迁移学习的使用非常有限。这些AI模型接受了强化学习的训练,强化学习是AI的一个分支,它是计算密集型的,并且需要大量的反复试验。在强化学习中,大多数新问题都是独特的,需要他们自己的 。
但总而言之,对于大多数深度学习应用程序(例如图像分类和自然语言处理),您很有可能可以通过大量的巧妙的迁移学习来获取捷径。
作者:AI国际站_今日头条
原文链接:https://www.toutiao.com/a6852096848329769476/





