本文转自雷锋网,如需转载请至雷锋网官网申请授权。
由于对人工智能偏见的担心日益凸显,从业者解释模型产出的预测结果的能力以及解释模型自身运作机制的能力变的越来越重要。幸运的是,已经有许多python工具集被开发出来,用以解决上述问题。下文我将对现有4个建立的比较完善的翻译和解释机器学习模型的工具包做简要的指导性描述。
这些工具包都可以通过pip来进行安装,拥有完善的文档,并且强调通过可视化来提升可解释性。
yellowbrick
这个工具包本质上,是scikit-learn的一个扩展,提供了一些非常实用且好看的机器学习模型可视化工具。`visualiser`对象是核心接口,是一个scikit-learn估计器,所以如果你之前熟悉scikit-learn的工作流程,那么将对此非常熟悉。
这个可视化工具覆盖了模型选择,特征重要性和模型性能分析等方面。
让我们看几个简短的例子。
该工具包可以通过pip安装,
- pip install yellowbrick
为了展示工具包中的一些特性,我们将利用scikit-learn中的红酒识别数据集。这个数据集包含13个特征以及3个目标类别。可以通过scikit-learn直接加载。在下面的代码里我引入数据集,并把转换成pandas dataframe。数据集可以直接被用来训练模型,并不需要其他的数据处理。
- import pandas as pd
- from sklearn import datasets
- wine_data = datasets.load_wine()
- df_wine = pd.DataFrame(wine_data.data,columns=wine_data.feature_names)
- df_wine['target'] = pd.Series(wine_data.target)
利用scikit-learn进一步将数据分为测试集合和训练集。
- import pandas as pd
- from sklearn import datasets
- wine_data = datasets.load_wine()
- df_wine = pd.DataFrame(wine_data.data,columns=wine_data.feature_names)
- df_wine['target'] = pd.Series(wine_data.target)
接下来,我们用yellowbrick的visualiser观察特征之间的相关性。
- import pandas as pd
- from sklearn import datasets
- wine_data = datasets.load_wine()
- df_wine = pd.DataFrame(wine_data.data,columns=wine_data.feature_names)
- df_wine['target'] = pd.Series(wine_data.target)

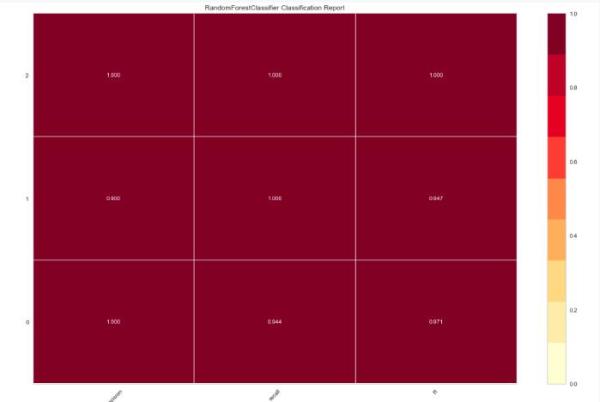
现在,我们拟合一个随机森林分类器,并通过另一个visualiser评价其性能。
- from yellowbrick.classifier import ClassificationReport
- from sklearn.ensemble import RandomForestClassifier
- model = RandomForestClassifier()
- visualizer = ClassificationReport(model, size=(1080, 720))
- visualizer.fit(X_train, y_train)
- visualizer.score(X_test, y_test)
- visualizer.poof()
ELI5
ELI5是另一个可视化工具包,在模型机器学习模型调试和解释其产出的预测结果方面非常有用。它能够同大多数通用的python机器学习工具包一起使用,包括scikit-learn和XGBoost,以及Keras。
让我们用ELI5来观察一下上面我们训练的模型的特征重要性。
- import eli5
- eli5.show_weights(model, feature_names = X.columns.tolist())
默认的,`show_weights`方法采用GAIN来计算权重,但你也可以传入其他`importance_type`来控制特征重要性的计算。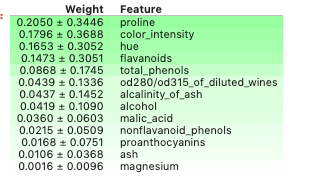
也可以通过`show_prediction`来观察某一个样本的预测结果的原因。
- from eli5 import show_predictionshow_prediction(model, X_train.iloc[1], feature_names = X.columns.tolist(),
- show_feature_values=True)

LIME
LIME(模型无关局部可解释)是一个用来解释模型做出的预测的工具包。LIME支持对多种分类器的单个样本预测进行解释,并且原生支持scikit-learn。
下面让我们用LIME对上述我们训练的模型的一些预测进行解释。
LIME可以用pip进行安装
- pip install lime
首先我们构建explainer,它通过训练数据集数组,模型中用到的特征名称和目标变量的类别名称作为初始化参数。
- import lime.lime_tabular
- explainer = lime.lime_tabular.LimeTabularExplainer(X_train.values, feature_names=X_train.columns.values.tolist(), class_names=y_train.unique())
接下来,我们创建一个lambda函数,它表示用模型预测一个样本。详见这个优秀的,更有深度的LIME教程。首先我们构建explainer,它通过训练数据集数组,模型中用到的特征名称和目标变量的类别名称作为初始化参数。
- predict_fn = lambda x: model.predict_proba(x).astype(float)
随后,我们利用explainer解释指定样本的预测结果。其结果如下。LIME通过可视化的结果,展示特征如果对得到的预测结果产生影响。
- exp = explainer.explain_instance(X_test.values[0], predict_fn, num_features=6)
- exp.show_in_notebook(show_all=False)

MLxtend
这个工具包包含一系列机器学习可用的工具函数。包括通过stacking和voting构建的分类器,模型的评估,特征的提取、特征工程和可视化。除了该工具包的文档,这篇论文也是理解工具包更多细节的好资源。
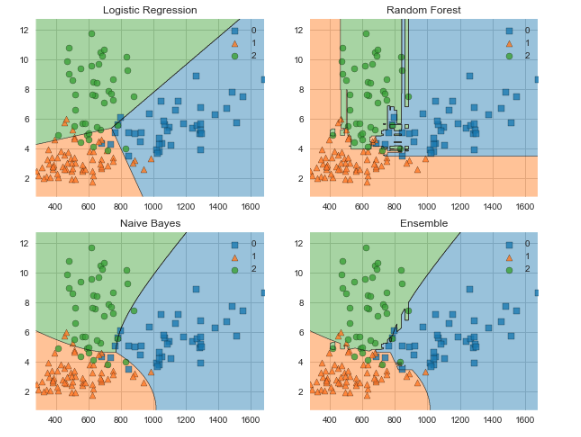
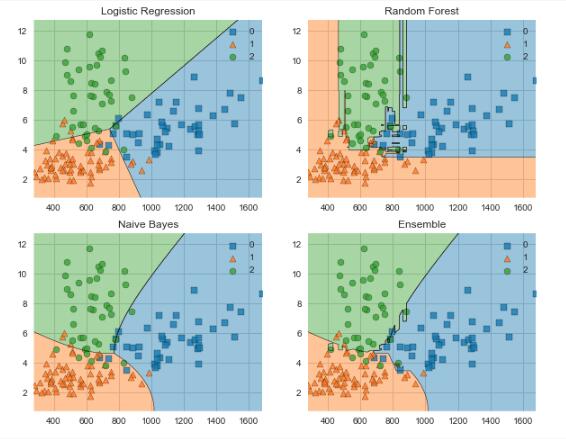
下面让我们利用MLxtend来比较Ensemble后的分类器的分类边界与组成他的子分类器的分类边界有什么不同。
同样MLxtend也可以通过pip安装。
- pip install mlxtend
引入一些工具包,
- from mlxtend.plotting import plot_decision_regions
- from mlxtend.classifier import EnsembleVoteClassifier
- import matplotlib.gridspec as gridspec
- import itertools
- from sklearn import model_selection
- from sklearn.linear_model import LogisticRegression
- from sklearn.naive_bayes import GaussianNB
- from sklearn.ensemble import RandomForestClassifier
下面的可视化工具一次只能接受两个特征作为输入,所以我们创建了数组[‘proline’, ‘color_intensity’]。因为这两个特征在上述利用ELI5分析时,具有最高的特征重要性。引入一些工具包,
- X_train_ml = X_train[['proline', 'color_intensity']].values
- y_train_ml = y_train.values
接下来,我们创建一些分类器,并在训练数据上进行拟合,通过MLxtend可视化他们的决策边界。输出来自下面的代码。
- clf1 = LogisticRegression(random_state=1)
- clf2 = RandomForestClassifier(random_state=1)
- clf3 = GaussianNB()
- eclf = EnsembleVoteClassifier(clfs=[clf1, clf2, clf3], weights=[1,1,1])
- value=1.5
- width=0.75
- gs = gridspec.GridSpec(2,2)
- fig = plt.figure(figsize=(10,8))
- labels = ['Logistic Regression', 'Random Forest', 'Naive Bayes', 'Ensemble']
- for clf, lab, grd in zip([clf1, clf2, clf3, eclf],
- labels,
- itertools.product([0, 1], repeat=2)):
- clf.fit(X_train_ml, y_train_ml)
- ax = plt.subplot(gs[grd[0], grd[1]])
- fig = plot_decision_regions(X=X_train_ml, y=y_train_ml, clf=clf)
- plt.title(lab)
以上绝对不是模型可解释和可视化工具包的完整列表。这篇博文罗列了包含其他有用的工具包的列表,值得一试。
感谢阅读!
作者:雷锋字幕组_雷锋网
原文链接:https://www.leiphone.com/news/202008/De6s56NId06cmdYr.html
转载请注明:www.ainoob.cn » 用于可解释机器学习的 Python 库






