OS 对象
os 模块提供了非常丰富的方法用来处理文件和目录。常用的方法如下表所示:
| 序号 | 方法及描述 |
|---|---|
| 1 | os.access(path, mode) 检验权限模式 |
| 2 | os.chdir(path) 改变当前工作目录 |
| 3 | os.chflags(path, flags) 设置路径的标记为数字标记。 |
| 4 | os.chmod(path, mode) 更改权限 |
| 5 | os.chown(path, uid, gid) 更改文件所有者 |
| 6 | os.chroot(path) 改变当前进程的根目录 |
| 7 | os.close(fd) 关闭文件描述符 fd |
| 8 | os.closerange(fd_low, fd_high) 关闭所有文件描述符,从 fd_low (包含) 到 fd_high (不包含), 错误会忽略 |
| 9 | os.dup(fd) 复制文件描述符 fd |
| 10 | os.dup2(fd, fd2) 将一个文件描述符 fd 复制到另一个 fd2 |
| 11 | os.fchdir(fd) 通过文件描述符改变当前工作目录 |
| 12 | os.fchmod(fd, mode) 改变一个文件的访问权限,该文件由参数fd指定,参数mode是Unix下的文件访问权限。 |
| 13 | os.fchown(fd, uid, gid) 修改一个文件的所有权,这个函数修改一个文件的用户ID和用户组ID,该文件由文件描述符fd指定。 |
| 14 | os.fdatasync(fd) 强制将文件写入磁盘,该文件由文件描述符fd指定,但是不强制更新文件的状态信息。 |
| 15 | os.fdopen(fd[, mode[, bufsize]]) 通过文件描述符 fd 创建一个文件对象,并返回这个文件对象 |
| 16 | os.fpathconf(fd, name) 返回一个打开的文件的系统配置信息。name为检索的系统配置的值,它也许是一个定义系统值的字符串,这些名字在很多标准中指定(POSIX.1, Unix 95, Unix 98, 和其它)。 |
| 17 | os.fstat(fd) 返回文件描述符fd的状态,像stat()。 |
| 18 | os.fstatvfs(fd) 返回包含文件描述符fd的文件的文件系统的信息,像 statvfs() |
| 19 | os.fsync(fd) 强制将文件描述符为fd的文件写入硬盘。 |
| 20 | os.ftruncate(fd, length) 裁剪文件描述符fd对应的文件, 所以它最大不能超过文件大小。 |
| 21 | os.getcwd() 返回当前工作目录 |
| 22 | os.getcwdu() 返回一个当前工作目录的Unicode对象 |
| 23 | os.isatty(fd) 如果文件描述符fd是打开的,同时与tty(-like)设备相连,则返回true, 否则False。 |
| 24 | os.lchflags(path, flags) 设置路径的标记为数字标记,类似 chflags(),但是没有软链接 |
| 25 | os.lchmod(path, mode) 修改连接文件权限 |
| 26 | os.lchown(path, uid, gid) 更改文件所有者,类似 chown,但是不追踪链接。 |
| 27 | os.link(src, dst) 创建硬链接,名为参数 dst,指向参数 src |
| 28 | os.listdir(path) 返回path指定的文件夹包含的文件或文件夹的名字的列表。 |
| 29 | os.lseek(fd, pos, how) 设置文件描述符 fd当前位置为pos, how方式修改: SEEK_SET 或者 0 设置从文件开始的计算的pos; SEEK_CUR或者 1 则从当前位置计算; os.SEEK_END或者2则从文件尾部开始. 在unix,Windows中有效 |
| 30 | os.lstat(path) 像stat(),但是没有软链接 |
| 31 | os.major(device) 从原始的设备号中提取设备major号码 (使用stat中的st_dev或者st_rdev field)。 |
| 32 | os.makedev(major, minor) 以major和minor设备号组成一个原始设备号 |
| 33 | os.makedirs(path[, mode]) 递归文件夹创建函数。像mkdir(), 但创建的所有intermediate-level文件夹需要包含子文件夹。 |
| 34 | os.minor(device) 从原始的设备号中提取设备minor号码 (使用stat中的st_dev或者st_rdev field )。 |
| 35 | os.mkdir(path[, mode]) 以数字mode的mode创建一个名为path的文件夹.默认的 mode 是 0777 (八进制)。 |
| 36 | os.mkfifo(path[, mode]) 创建命名管道,mode 为数字,默认为 0666 (八进制) |
| 37 | os.mknod(filename[, mode=0600, device]) 创建一个名为filename文件系统节点(文件,设备特别文件或者命名pipe)。 |
| 38 | os.open(file, flags[, mode]) 打开一个文件,并且设置需要的打开选项,mode参数是可选的 |
| 39 | os.openpty() 打开一个新的伪终端对。返回 pty 和 tty的文件描述符。 |
| 40 | os.pathconf(path, name) 返回相关文件的系统配置信息。 |
| 41 | os.pipe() 创建一个管道. 返回一对文件描述符(r, w) 分别为读和写 |
| 42 | os.popen(command[, mode[, bufsize]]) 从一个 command 打开一个管道 |
| 43 | os.read(fd, n) 从文件描述符 fd 中读取最多 n 个字节,返回包含读取字节的字符串,文件描述符 fd对应文件已达到结尾, 返回一个空字符串。 |
| 44 | os.readlink(path) 返回软链接所指向的文件 |
| 45 | os.remove(path) 删除路径为path的文件。如果path 是一个文件夹,将抛出OSError; 查看下面的rmdir()删除一个 directory。 |
| 46 | os.removedirs(path) 递归删除目录。 |
| 47 | os.rename(src, dst) 重命名文件或目录,从 src 到 dst |
| 48 | os.renames(old, new) 递归地对目录进行更名,也可以对文件进行更名。 |
| 49 | os.rmdir(path) 删除path指定的空目录,如果目录非空,则抛出一个OSError异常。 |
| 50 | os.stat(path) 获取path指定的路径的信息,功能等同于C API中的stat()系统调用。 |
| 51 | os.stat_float_times([newvalue]) 决定stat_result是否以float对象显示时间戳 |
| 52 | os.statvfs(path) 获取指定路径的文件系统统计信息 |
| 53 | os.symlink(src, dst) 创建一个软链接 |
| 54 | os.tcgetpgrp(fd) 返回与终端fd(一个由os.open()返回的打开的文件描述符)关联的进程组 |
| 55 | os.tcsetpgrp(fd, pg) 设置与终端fd(一个由os.open()返回的打开的文件描述符)关联的进程组为pg。 |
| 56 | os.tempnam([dir[, prefix]]) Python3 中已删除。返回唯一的路径名用于创建临时文件。 |
| 57 | os.tmpfile() Python3 中已删除。返回一个打开的模式为(w+b)的文件对象 .这文件对象没有文件夹入口,没有文件描述符,将会自动删除。 |
| 58 | os.tmpnam() Python3 中已删除。为创建一个临时文件返回一个唯一的路径 |
| 59 | os.ttyname(fd) 返回一个字符串,它表示与文件描述符fd 关联的终端设备。如果fd 没有与终端设备关联,则引发一个异常。 |
| 60 | os.unlink(path) 删除文件路径 |
| 61 | os.utime(path, times) 返回指定的path文件的访问和修改的时间。 |
| 62 | os.walk(top[, topdown=True[, onerror=None[, followlinks=False]]]) 输出在文件夹中的文件名通过在树中游走,向上或者向下。 |
| 63 | os.write(fd, str) 写入字符串到文件描述符 fd中. 返回实际写入的字符串长度 |
| 64 | os.path 模块 获取文件的属性信息。 |
file 对象
file 对象使用 open 函数来创建,下表列出了 file 对象常用的函数:
| 序号 | 方法及描述 |
|---|---|
| 1 | file.close()关闭文件。关闭后文件不能再进行读写操作。 |
| 2 | file.flush()刷新文件内部缓冲,直接把内部缓冲区的数据立刻写入文件, 而不是被动的等待输出缓冲区写入。 |
| 3 | file.fileno()返回一个整型的文件描述符(file descriptor FD 整型), 可以用在如os模块的read方法等一些底层操作上。 |
| 4 | file.isatty()如果文件连接到一个终端设备返回 True,否则返回 False。 |
| 5 | file.next()返回文件下一行。 |
| 6 | file.read([size])从文件读取指定的字节数,如果未给定或为负则读取所有。 |
| 7 | file.readline([size])读取整行,包括 “\n” 字符。 |
| 8 | file.readlines([sizeint])读取所有行并返回列表,若给定sizeint>0,返回总和大约为sizeint字节的行, 实际读取值可能比 sizeint 较大, 因为需要填充缓冲区。 |
| 9 | file.seek(offset[, whence])设置文件当前位置 |
| 10 | file.tell()返回文件当前位置。 |
| 11 | file.truncate([size])从文件的首行首字符开始截断,截断文件为 size 个字符,无 size 表示从当前位置截断;截断之后后面的所有字符被删除,其中 Widnows 系统下的换行代表2个字符大小。 |
| 12 | file.write(str)将字符串写入文件,返回的是写入的字符长度。 |
| 13 | file.writelines(sequence)向文件写入一个序列字符串列表,如果需要换行则要自己加入每行的换行符。 |
File 读和写
open() 将会返回一个 file 对象,基本语法格式如下:
open(filename, mode)
- filename:包含了你要访问的文件名称的字符串值。
- mode:决定了打开文件的模式:只读,写入,追加等。所有可取值见如下的完全列表。这个参数是非强制的,默认文件访问模式为只读(r)。
不同模式打开文件的完全列表:
| 模式 | 描述 |
|---|---|
| r | 以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式。 |
| rb | 以二进制格式打开一个文件用于只读。文件指针将会放在文件的开头。 |
| r+ | 打开一个文件用于读写。文件指针将会放在文件的开头。 |
| rb+ | 以二进制格式打开一个文件用于读写。文件指针将会放在文件的开头。 |
| w | 打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| wb | 以二进制格式打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| w+ | 打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| wb+ | 以二进制格式打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| a | 打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| ab | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| a+ | 打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写。 |
| ab+ | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。如果该文件不存在,创建新文件用于读写。 |
下图很好的总结了这几种模式:
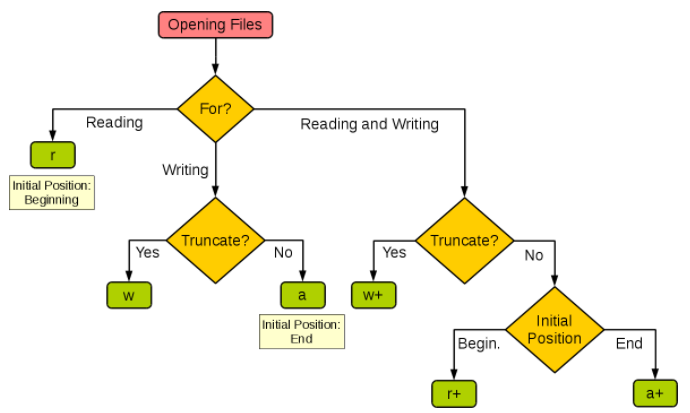
| 模式 | r | r+ | w | w+ | a | a+ |
|---|---|---|---|---|---|---|
| 读 | + | + | + | + | ||
| 写 | + | + | + | + | + | |
| 创建 | + | + | + | + | ||
| 覆盖 | + | + | ||||
| 指针在开始 | + | + | + | + | ||
| 指针在结尾 | + | + |
以下实例将字符串写入到文件 foo.txt 中:
#!/usr/bin/python3
# 打开一个文件
f = open("/tmp/foo.txt", "w")
f.write( "Python 是一个非常好的语言。\n是的,的确非常好!!\n" )
# 关闭打开的文件
f.close()- 第一个参数为要打开的文件名。
- 第二个参数描述文件如何使用的字符。 mode 可以是 ‘r’ 如果文件只读, ‘w’ 只用于写 (如果存在同名文件则将被删除), 和 ‘a’ 用于追加文件内容; 所写的任何数据都会被自动增加到末尾. ‘r+’ 同时用于读写。 mode 参数是可选的; ‘r’ 将是默认值。
此时打开文件 foo.txt,显示如下:
$ cat /tmp/foo.txt
Python 是一个非常好的语言。
是的,的确非常好!!
文件对象的方法
本节中剩下的例子假设已经创建了一个称为 f 的文件对象。
f.read()
为了读取一个文件的内容,调用 f.read(size), 这将读取一定数目的数据, 然后作为字符串或字节对象返回。
size 是一个可选的数字类型的参数。 当 size 被忽略了或者为负, 那么该文件的所有内容都将被读取并且返回。
以下实例假定文件 foo.txt 已存在(上面实例中已创建):
#!/usr/bin/python3
# 打开一个文件
f = open("/tmp/foo.txt", "r")
str = f.read()
print(str)
# 关闭打开的文件
f.close()执行以上程序,输出结果为:
Python 是一个非常好的语言。
是的,的确非常好!!
f.readline()
f.readline() 会从文件中读取单独的一行。换行符为 ‘\n’。f.readline() 如果返回一个空字符串, 说明已经已经读取到最后一行。
#!/usr/bin/python3
# 打开一个文件
f = open("/tmp/foo.txt", "r")
str = f.readline()
print(str)
# 关闭打开的文件
f.close()执行以上程序,输出结果为:
Python 是一个非常好的语言。
f.readlines()
f.readlines() 将返回该文件中包含的所有行。
如果设置可选参数 sizehint, 则读取指定长度的字节, 并且将这些字节按行分割。
#!/usr/bin/python3
# 打开一个文件
f = open("/tmp/foo.txt", "r")
str = f.readlines()
print(str)
# 关闭打开的文件
f.close()执行以上程序,输出结果为:
['Python 是一个非常好的语言。\n', '是的,的确非常好!!\n']
另一种方式是迭代一个文件对象然后读取每行:
#!/usr/bin/python3
# 打开一个文件f = open("/tmp/foo.txt", "r")
for line in f:
print(line, end='')
# 关闭打开的文件
f.close()执行以上程序,输出结果为:
Python 是一个非常好的语言。
是的,的确非常好!!
这个方法很简单, 但是并没有提供一个很好的控制。 因为两者的处理机制不同, 最好不要混用。
f.write()
f.write(string) 将 string 写入到文件中, 然后返回写入的字符数。
#!/usr/bin/python3
# 打开一个文件f = open("/tmp/foo.txt", "w")
num = f.write( "Python 是一个非常好的语言。\n是的,的确非常好!!\n" )
print(num)
# 关闭打开的文件
f.close()执行以上程序,输出结果为:
29
如果要写入一些不是字符串的东西, 那么将需要先进行转换:
#!/usr/bin/python3
# 打开一个文件
f = open("/tmp/foo1.txt", "w")
value = ('www.ainoob.com', 14)
s = str(value)
f.write(s)
# 关闭打开的文件
f.close()执行以上程序,打开 foo1.txt 文件:
$ cat /tmp/foo1.txt
('www.ainoob.com', 14)
f.tell()
f.tell() 返回文件对象当前所处的位置, 它是从文件开头开始算起的字节数。
f.seek()
如果要改变文件当前的位置, 可以使用 f.seek(offset, from_what) 函数。
from_what 的值, 如果是 0 表示开头, 如果是 1 表示当前位置, 2 表示文件的结尾,例如:
- seek(x,0) : 从起始位置即文件首行首字符开始移动 x 个字符
- seek(x,1) : 表示从当前位置往后移动x个字符
- seek(-x,2):表示从文件的结尾往前移动x个字符
from_what 值为默认为0,即文件开头。下面给出一个完整的例子:
>>> f = open('/tmp/foo.txt', 'rb+')
>>> f.write(b'0123456789abcdef')
16
>>> f.seek(5) # 移动到文件的第六个字节
5
>>> f.read(1)
b'5'
>>> f.seek(-3, 2) # 移动到文件的倒数第三字节
13
>>> f.read(1)
b'd'
f.close()
在文本文件中 (那些打开文件的模式下没有 b 的), 只会相对于文件起始位置进行定位。
当你处理完一个文件后, 调用 f.close() 来关闭文件并释放系统的资源,如果尝试再调用该文件,则会抛出异常。
>>> f.close()
>>> f.read()
Traceback (most recent call last):
File "<stdin>", line 1, in ?
ValueError: I/O operation on closed file
当处理一个文件对象时, 使用 with 关键字是非常好的方式。在结束后, 它会帮你正确的关闭文件。 而且写起来也比 try – finally 语句块要简短:
>>> with open('/tmp/foo.txt', 'r') as f:
... read_data = f.read()
>>> f.closedTrue
文件对象还有其他方法, 如 isatty() 和 trucate(), 但这些通常比较少用。
pickle 模块
python的pickle模块实现了基本的数据序列和反序列化。
通过pickle模块的序列化操作我们能够将程序中运行的对象信息保存到文件中去,永久存储。
通过pickle模块的反序列化操作,我们能够从文件中创建上一次程序保存的对象。
基本接口:
pickle.dump(obj, file, [,protocol])
有了 pickle 这个对象, 就能对 file 以读取的形式打开:
x = pickle.load(file)
注解:从 file 中读取一个字符串,并将它重构为原来的python对象。
file: 类文件对象,有read()和readline()接口。
实例1:
#!/usr/bin/python3
import pickle
# 使用pickle模块将数据对象保存到文件
data1 = {'a': [1, 2.0, 3, 4+6j],
'b': ('string', u'Unicode string'),
'c': None}
selfref_list = [1, 2, 3]
selfref_list.append(selfref_list)
output = open('data.pkl', 'wb')
# Pickle dictionary using protocol 0.
pickle.dump(data1, output)
# Pickle the list using the highest protocol available.
pickle.dump(selfref_list, output, -1)
output.close()实例2:
#!/usr/bin/python3
import pprint, pickle
#使用pickle模块从文件中重构python对象
pkl_file = open('data.pkl', 'rb')
data1 = pickle.load(pkl_file)
pprint.pprint(data1)
data2 = pickle.load(pkl_file)
pprint.pprint(data2)
pkl_file.close()转载请注明:www.ainoob.cn » Python OS和File





