Pandas是基于NumPy的一个非常好用的库,正如名字一样,人见人爱。之所以如此,就在于不论是读取、处理数据,用它都非常简单。
基本的数据结构
Pandas有两种自己独有的基本数据结构。读者应该注意的是,它固然有着两种数据结构,因为它依然是python的一个库,所以,python中有的数据类型在这里依然适用,也同样还可以使用类自己定义数据类型。只不过,Pandas里面又定义了两种数据类型:Series和DataFrame,它们让数据操作更简单了。
以下操作都是基于:

为了省事,后面就不在显示了。并且如果你跟我一样是使用ipython notebook,只需要开始引入模块即可。
Series
Series就如同列表一样,一系列数据,每个数据对应一个索引值。比如这样一个列表:[9, 3, 8],如果跟索引值写到一起,就是:
| data | 9 | 3 | 8 |
|---|---|---|---|
| index | 0 | 1 | 2 |
这种样式我们已经熟悉了,不过,在有些时候,需要把它竖过来表示:
| index | data |
|---|---|
| 0 | 9 |
| 1 | 3 |
| 2 | 8 |
上面两种,只是表现形式上的差别罢了。
Series就是“竖起来”的list:
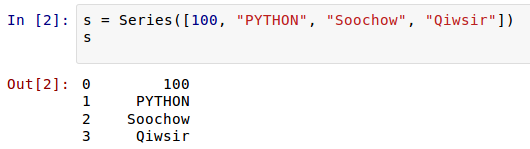
另外一点也很像列表,就是里面的元素的类型,由你任意决定(其实是由需要来决定)。
这里,我们实质上创建了一个Series对象,这个对象当然就有其属性和方法了。比如,下面的两个属性依次可以显示Series对象的数据值和索引:

列表的索引只能是从0开始的整数,Series数据类型在默认情况下,其索引也是如此。不过,区别于列表的是,Series可以自定义索引:


自定义索引,的确比较有意思。就凭这个,也是必须的。
每个元素都有了索引,就可以根据索引操作元素了。还记得list中的操作吗?Series中,也有类似的操作。先看简单的,根据索引查看其值和修改其值:
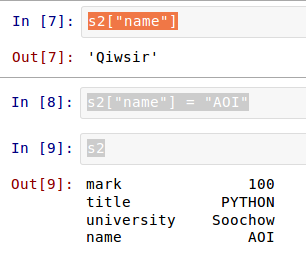
这是不是又有点类似dict数据了呢?的确如此。看下面就理解了。
读者是否注意到,前面定义Series对象的时候,用的是列表,即Series()方法的参数中,第一个列表就是其数据值,如果需要定义index,放在后面,依然是一个列表。除了这种方法之外,还可以用下面的方法定义Series对象:
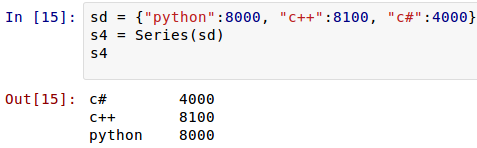
现在是否理解为什么前面那个类似dict了?因为本来就是可以这样定义的。
这时候,索引依然可以自定义。Pandas的优势在这里体现出来,如果自定义了索引,自定的索引会自动寻找原来的索引,如果一样的,就取原来索引对应的值,这个可以简称为“自动对齐”。
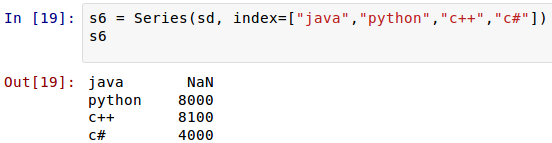
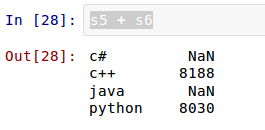
在sd中,只有'python':8000, 'c++':8100, 'c#':4000,没有”java”,但是在索引参数中有,于是其它能够“自动对齐”的照搬原值,没有的那个”java”,依然在新Series对象的索引中存在,并且自动为其赋值NaN。在Pandas中,如果没有值,都对齐赋给NaN。来一个更特殊的:
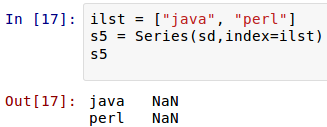
新得到的Series对象索引与sd对象一个也不对应,所以都是NaN。
Pandas有专门的方法来判断值是否为空。
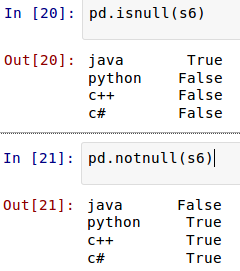
此外,Series对象也有同样的方法:
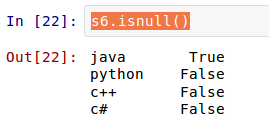
其实,对索引的名字,是可以从新定义的:
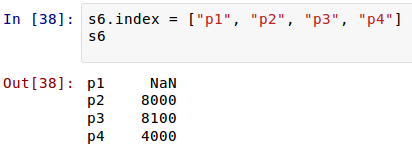
对于Series数据,也可以做类似下面的运算(关于运算,后面还要详细介绍):
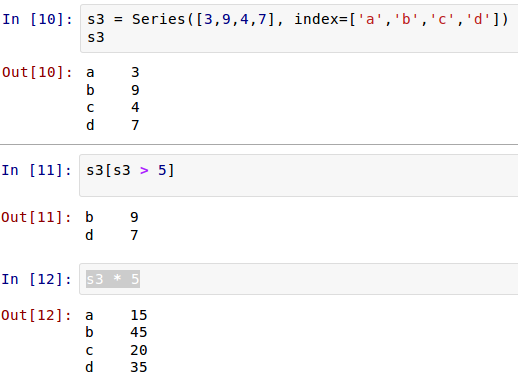
上面的演示中,都是在ipython notebook中进行的,所以截图了。在学习Series数据类型同时了解了ipyton notebook。对于后面的所有操作,读者都可以在ipython notebook中进行。但是,我的讲述可能会在python交互模式中进行。
DataFrame
DataFrame是一种二维的数据结构,非常接近于电子表格或者类似mysql数据库的形式。它的竖行称之为columns,横行跟前面的Series一样,称之为index,也就是说可以通过columns和index来确定一个主句的位置。(有人把 DataFrame翻译为“数据框”,是不是还可以称之为“筐”呢?向里面装数据嘛。)
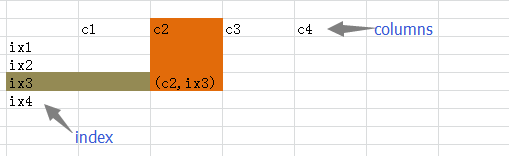
下面的演示,是在python交互模式下进行,读者仍然可以在ipython notebook环境中测试。
>>> import pandas as pd
>>> from pandas import Series, DataFrame
>>> data = {"name":["yahoo","google","facebook"], "marks":[200,400,800], "price":[9, 3, 7]}
>>> f1 = DataFrame(data)
>>> f1
marks name price
0 200 yahoo 9
1 400 google 3
2 800 facebook 7
这是定义一个DataFrame对象的常用方法——使用dict定义。字典的“键”(”name”,”marks”,”price”)就是DataFrame的columns的值(名称),字典中每个“键”的“值”是一个列表,它们就是那一竖列中的具体填充数据。上面的定义中没有确定索引,所以,按照惯例(Series中已经形成的惯例)就是从0开始的整数。从上面的结果中很明显表示出来,这就是一个二维的数据结构(类似excel或者mysql中的查看效果)。
上面的数据显示中,columns的顺序没有规定,就如同字典中键的顺序一样,但是在DataFrame中,columns跟字典键相比,有一个明显不同,就是其顺序可以被规定,向下面这样做:
>>> f2 = DataFrame(data, columns=['name','price','marks'])
>>> f2
name price marks
0 yahoo 9 200
1 google 3 400
2 facebook 7 800
跟Series类似的,DataFrame数据的索引也能够自定义。
>>> f3 = DataFrame(data, columns=['name', 'price', 'marks', 'debt'], index=['a','b','c','d'])
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/usr/lib/pymodules/python2.7/pandas/core/frame.py", line 283, in __init__
mgr = self._init_dict(data, index, columns, dtype=dtype)
File "/usr/lib/pymodules/python2.7/pandas/core/frame.py", line 368, in _init_dict
mgr = BlockManager(blocks, axes)
File "/usr/lib/pymodules/python2.7/pandas/core/internals.py", line 285, in __init__
self._verify_integrity()
File "/usr/lib/pymodules/python2.7/pandas/core/internals.py", line 367, in _verify_integrity
assert(block.values.shape[1:] == mgr_shape[1:])
AssertionError
报错了。这个报错信息就太不友好了,也没有提供什么线索。这就是交互模式的不利之处。修改之,错误在于index的值——列表——的数据项多了一个,data中是三行,这里给出了四个项([‘a’,’b’,’c’,’d’])。
>>> f3 = DataFrame(data, columns=['name', 'price', 'marks', 'debt'], index=['a','b','c'])
>>> f3
name price marks debt
a yahoo 9 200 NaN
b google 3 400 NaN
c facebook 7 800 NaN
读者还要注意观察上面的显示结果。因为在定义f3的时候,columns的参数中,比以往多了一项(‘debt’),但是这项在data这个字典中并没有,所以debt这一竖列的值都是空的,在Pandas中,空就用NaN来代表了。
定义DataFrame的方法,除了上面的之外,还可以使用“字典套字典”的方式。
>>> newdata = {"lang":{"firstline":"python","secondline":"java"}, "price":{"firstline":8000}}
>>> f4 = DataFrame(newdata)
>>> f4
lang price
firstline python 8000
secondline java NaN
在字典中就规定好数列名称(第一层键)和每横行索引(第二层字典键)以及对应的数据(第二层字典值),也就是在字典中规定好了每个数据格子中的数据,没有规定的都是空。
>>> DataFrame(newdata, index=["firstline","secondline","thirdline"])
lang price
firstline python 8000
secondline java NaN
thirdline NaN NaN
如果额外确定了索引,就如同上面显示一样,除非在字典中有相应的索引内容,否则都是NaN。
前面定义了DataFrame数据(可以通过两种方法),它也是一种对象类型,比如变量f3引用了一个对象,它的类型是DataFrame。承接以前的思维方法:对象有属性和方法。
>>> f3.columns
Index(['name', 'price', 'marks', 'debt'], dtype=object)
DataFrame对象的columns属性,能够显示素有的columns名称。并且,还能用下面类似字典的方式,得到某竖列的全部内容(当然包含索引):
>>> f3['name']
a yahoo
b google
c facebook
Name: name
这是什么?这其实就是一个Series,或者说,可以将DataFrame理解为是有一个一个的Series组成的。
一直耿耿于怀没有数值的那一列,下面的操作是统一给那一列赋值:
>>> f3['debt'] = 89.2
>>> f3
name price marks debt
a yahoo 9 200 89.2
b google 3 400 89.2
c facebook 7 800 89.2
除了能够统一赋值之外,还能够“点对点”添加数值,结合前面的Series,既然DataFrame对象的每竖列都是一个Series对象,那么可以先定义一个Series对象,然后把它放到DataFrame对象中。如下:
>>> sdebt = Series([2.2, 3.3], index=["a","c"]) #注意索引
>>> f3['debt'] = sdebt
将Series对象(sdebt变量所引用) 赋给f3[‘debt’]列,Pandas的一个重要特性——自动对齐——在这里起做用了,在Series中,只有两个索引(”a”,”c”),它们将和DataFrame中的索引自动对齐。于是乎:
>>> f3
name price marks debt
a yahoo 9 200 2.2
b google 3 400 NaN
c facebook 7 800 3.3
自动对齐之后,没有被复制的依然保持NaN。
还可以更精准的修改数据吗?当然可以,完全仿照字典的操作:
>>> f3["price"]["c"]= 300
>>> f3
name price marks debt
a yahoo 9 200 2.2
b google 3 400 NaN
c facebook 300 800 3.3
这些操作是不是都不陌生呀,这就是Pandas中的两种数据对象。
转载请注明:www.ainoob.cn » 零基础学Python:Pandas使用(1)




