通过这款名为 PlaidML 的工具,不论英伟达、AMD 还是英特尔显卡都可以轻松搞定深度学习训练了。

众所周知,深度学习是因为 2010 年代英伟达 GPU 算力提升而快速发展起来的,不过如今市面上还有多种品牌的显卡,它们同样拥有不错的性能,后者能不能成为 AI 模型算力的基础呢?

如果答案是肯定的,那我们的笔记本电脑岂不就可以用来跑深度学习模型了,尤其是让我们下了血本的 MacBookPro。
MacBookPro 在科技圈覆盖面颇广,质量也不错,不能拿来做深度学习实在可惜。在选购 MacBook 的过程中,有些人会为了独立显卡而多花点钱,但到了做深度学习的时候却发现这钱花得很冤枉,因为长期以来,多数机器学习模型只能通过通用 GPU 库 CUDA 使用英伟达的 GPU。
但我们真的别无选择吗?medium 的一位博主表示,事实并非如此。一款名为 PlaidML 的深度学习框架可以破解这个困境。

为什么要用 GPU 做并行计算?
以建房子为例:如果单独完成,你需要花费 400 个小时,但如果你雇一个建筑工人,工期就可能减半。雇佣的工人越多,你的房子建得也越快。这就是阿姆达尔定律所揭示的内容。它是一个计算机科学界的经验法则,代表了处理器并行运算之后效率提升的能力。

那么为什么要用 GPU 呢?最初 GPU 并不是为深度学习专门设计的,但并行计算的本质似乎与图形处理类似。单个 GPU 的核心虽然在性能上弱一些,但在处理大数据块的算法上比 CPU 更高效,因为它们具有高度并行的结构,而且核的数量也非常多。由于图形处理和深度学习在本质上的相似性,GPU 就成为了深度学习和并行计算的首选。
除了 CUDA 就没得选了吗?
不过要想用上 GPU 的并行能力,英伟达的 CUDA 就不可回避,这种通用并行计算库是做深度学习所必须的。目前,之所以高性能云计算、DL 服务器都采用英伟达 GPU,主要原因还是在 CUDA。
如果想要充分利用笔记本的并行能力,且 N 卡又配不起,那么这篇文章介绍的 PlaidML 就非常合适了。
项目地址:https://github.com/plaidml/plaidml
PlaidML 是 Vertex.AI 2017 年开源的一款深度学习工具包。2018 年,英特尔收购了 Vertex.AI。之后 PlaidML 0.3.3 发布,开发者可以借助 Keras 在自己的 AMD 和英特尔 GPU 上完成并行深度学习任务。上个月,Vertex.AI 又发布了 PlaidML 的 0.7.0 版本。

PlaidML 是一种可移植的张量编译器,可以在笔记本电脑、嵌入式设备或其他设备上进行深度学习。重要的是,它并不依赖于 CUDA,而是 OpenCL 这种开放标准。
OpenCL 通用并行计算开放标准并不是为 N 卡专门设计的,因此不论你的笔记本 GPU 是 AMD、 Intel,还是 NVIDIA,它都能支持。

很多读者可能认为,OpenCL 的生态没有 CUDA 成熟,可能在稳定性与开发速度上都没那么快。但是,我们可以把复杂的底层机制都交给 PlaidML,我们只需要用就行了。
甚至 PlaidML 我们都不需要接触,它已经集成到了常见的深度学习框架中,并允许用户在任何硬件中调用它。目前 PlaidML 已经支持 Keras、ONNX 和 nGraph 等工具,直接用 Keras 建个模,MacBook 轻轻松松调用 GPU。
下面我们开始进入正题:如何用自己笔记本电脑的 GPU 运行一个简单的 CNN。
用笔记本 GPU 运行一个神经网络
安装和设置 PlaidML 和相关组件
首先,我们要确保自己的笔记本电脑安装了 Python 3 工作环境。作者建议在虚拟环境下运行以下代码:
- # install python3 virtualenv if you haven’t done so:
- pip3 install virtualenv
- # Now create and activate a virtual environment for the case
- python3 -m venv plaidml-venv
- source plaidml-venv/bin/activate
- # Install PlaidML with Keras
- pip install -U plaidml-keras
记住一点,标准 TensorFlow 框架下的 Keras 无法使用 PlaidML,需要安装 PlaidML 定制的 Keras。
- # Now setup PlaidML to use the right device
- plaidml-setup

设置 PlaidML 第二步。
现在得到了自己选择的设备列表。以作者的电脑 Macbook Pro 15’2018 为例,设备列表如下:
- CPU
- 英特尔 UHD Graphics 630 显卡
- AMD Radeon pro 560x 显卡
最后,键入「y」或「nothing」,返回保存设置。这样以来,我们就已安装所有设备,并且可以使用 GPU 来运行深度学习项目了。
在 fashion mnist 上创建 CNN 分类器
首先,启动 Jupyter Notebook。
- Jupyter Notebook
然后按顺序运行以下代码,将 PlaidML 用作 Keras 后端,否则会默认使用 TensorFlow。
- # Importing PlaidML. Make sure you follow this order
- import plaidml.keras
- plaidml.keras.install_backend()
- import os
- os.environ["KERAS_BACKEND"] = "plaidml.keras.backend"
现在就可以导入包,并下载 fashion 数据集。
- import keras
- from keras.models import Sequential
- from keras.layers import Dense, Dropout, Flatten
- from keras.layers import Conv2D, MaxPooling2D
- from keras import backend as K
- # Download fashion dataset from Keras
- fashion_mnist = keras.datasets.fashion_mnist
- (x_train, y_train), (x_test, y_test) = keras.datasets.fashion_mnist.load_data()
- # Reshape and normalize the data
- x_train = x_train.astype('float32').reshape(60000,28,28,1) / 255
- x_test = x_test.astype('float32').reshape(10000,28,28,1) / 255
接下来使用 Keras 的序贯模块来创建一个简单的 CNN,并编译它。
- # Build a CNN model. You should see "INFO:plaidml:Opening device xxx" after you run this chunk
- model = keras.Sequential()
- model.add(keras.layers.Conv2D(filters=64, kernel_size=2, padding='same', activation='relu', input_shape=(28,28,1)))
- model.add(keras.layers.MaxPooling2D(pool_size=2))
- model.add(keras.layers.Dropout(0.3))
- model.add(keras.layers.Conv2D(filters=32, kernel_size=2, padding='same', activation='relu'))
- model.add(keras.layers.MaxPooling2D(pool_size=2))
- model.add(keras.layers.Dropout(0.3))
- model.add(keras.layers.Flatten())
- model.add(keras.layers.Dense(256, activation='relu'))
- model.add(keras.layers.Dropout(0.5))
- model.add(keras.layers.Dense(10, activation='softmax'))
- # Compile the model
- model.compile(optimizer='adam',
- loss=keras.losses.sparse_categorical_crossentropy,
- metrics=['accuracy'])
现在我们拟合模型,测试一下它的准确率。
- # Fit the model on training set
- model.fit(x_train, y_train,
- batch_size=64,
- epochs=10)
- # Evaluate the model on test set
- score = model.evaluate(x_test, y_test, verbose=0)
- # Print test accuracy
- print('\n', 'Test accuracy:', score[1])

更多结果。
我们训练的卷积神经网络模型在时尚分类任务上达到了 91% 的准确率,训练只用了 2 分钟!这个数字可能看起来并不惊艳,但想想 CPU 训练要多久吧:

用 CPU 完成相同的任务要用 2219 秒(约 37 分钟),MAC 风扇期间还会疯狂输出。
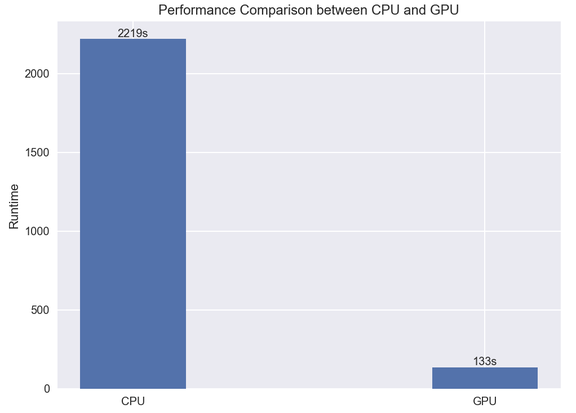
从以上结论中我们可以看到,借助 Macbook Pro 搭载的 GPU 进行深度学习计算要比简单地用 CPU 快 15 倍。通过 PlaidML,使用自己的笔记本电脑训练深度学习模型将变得更加简单。
截至目前(2020 年 2 月),PlaidML 可以和各种品牌的 GPU 兼容,在使用英伟达显卡时也无需 CUDA/cuDNN,也能达到类似的性能。
在 PlaidML 的 GitHub 页面上你能看到更多的 demo 和相关项目,相信随着这一工具的不断发展,它可以支持的算法也会越来越多。我们在自己的笔记本上,也能快速试验个小模型。
作者:Synced_机器之心
原文链接:https://mp.weixin.qq.com/s?__biz=MzA3MzI4MjgzMw==&mid=2650781257&idx=1&sn=fcc51bb5a09400eba9fc0f27a281b84b&chksm=871a7237b06dfb217184b33eb1585789af515cbe945ce1859dd79c16b5447a3b86f209d2ec6e&mpshare=1&
转载请注明:www.ainoob.cn » 这个深度学习工具支持所有品牌GPU




